Dueño de mis datos - Capítulo Facebook - Parte II
¡Text Mining! Es hora de entrarle a la onda de los diccionarios de palabras, los análisis de sentimientos y las gráficas de nube de palabras.
Si quieren ver como obtener los datos con los que vamos a trabajar pueden verlo en la primera parte de esta serie.
Solo para recordar el objetivo de esta serie:
… vamos a jugar con todos los posteos que hice en Facebook y todos los comentarios que puse a posteos de otras personas. Aprovechando el gran curso de Text Mining que @jmtoral nos dio durante la cuarentena, vamos a analizar mis textos e intentar encontrar algunas cosas interesantes. Al final, y porque nos gusta mucho, haremos gráficas y más gráficas.
Un poco de contexto. O sea, mi Disclaimer
La cuarentena me ha pegado duro como a la mayoría de la gente. Si le suman que previo a ella ya tenía 4 meses encerrado por una lesión, se podrán imaginar lo desesperado que he llegado a estar.
Una forma en que yo logro manejar la ansiedad es estudiando, aprendiendo cosas nuevas y pasando horas practicándolas. Entiendo que eso no es para todos pero se los comparto por si les es de ayuda.
Cuando @jmtoral avisó en Twitter que iba a dar un curso de Minería de Texto no dudé ni tantito en escribirme. Era un tema que desconocía por completo y que pensé que podría aplicar con los datos de Facebook que tenía parados desde hace unos meses.
Dicho esto, por favor tengan en mente que lo que aqui haremos es una acercamiento al tema con las cosas que entendí y ,seguro también, con los errores de las cosas que aún no entiendo por completo. Lo importante es que se queden con una noción y empiecen a jugar.
Guidelines para la visualización
Esta vez no hay bocetos en papel pero vamos a tocar un tema nuevo: los guidelines.
Para las visualizaciones de los Pats y de Spotify me tuve que crear un par de themes para que las visualizaciones fueran consistentes. Eso son las guidelines. Sin embargo, estas gúias de estilo no son enchiladas. En aquellas ocasiones tardé mucho en elegir colores, tamaños de fuentes, espacios entre márgenes, etc.
Todos sabemos que usar Comic Sans no es profesional para una dataviz, pero ¿por qué? Si van a hacer una gráfica, ¿porqué usarían Calibri, Arial o Times New Roman? Si van a combinar fuentes, ¿cuál va mejor con cúal?
Afortunadamente hay un montón de UX, VD, entre otras profesiones, que se dedican a crear estas guías para sus organizaciones y muchas de ellas con públicas. Hay una buena lista aquí que tenemos a la mano gracias a la Data Visualization Society. Para este ejercicio decidí tomar como referencia la guía del Urban Institute.
Les dejo unos pedacitos de lo que pueden encontrar ahí:
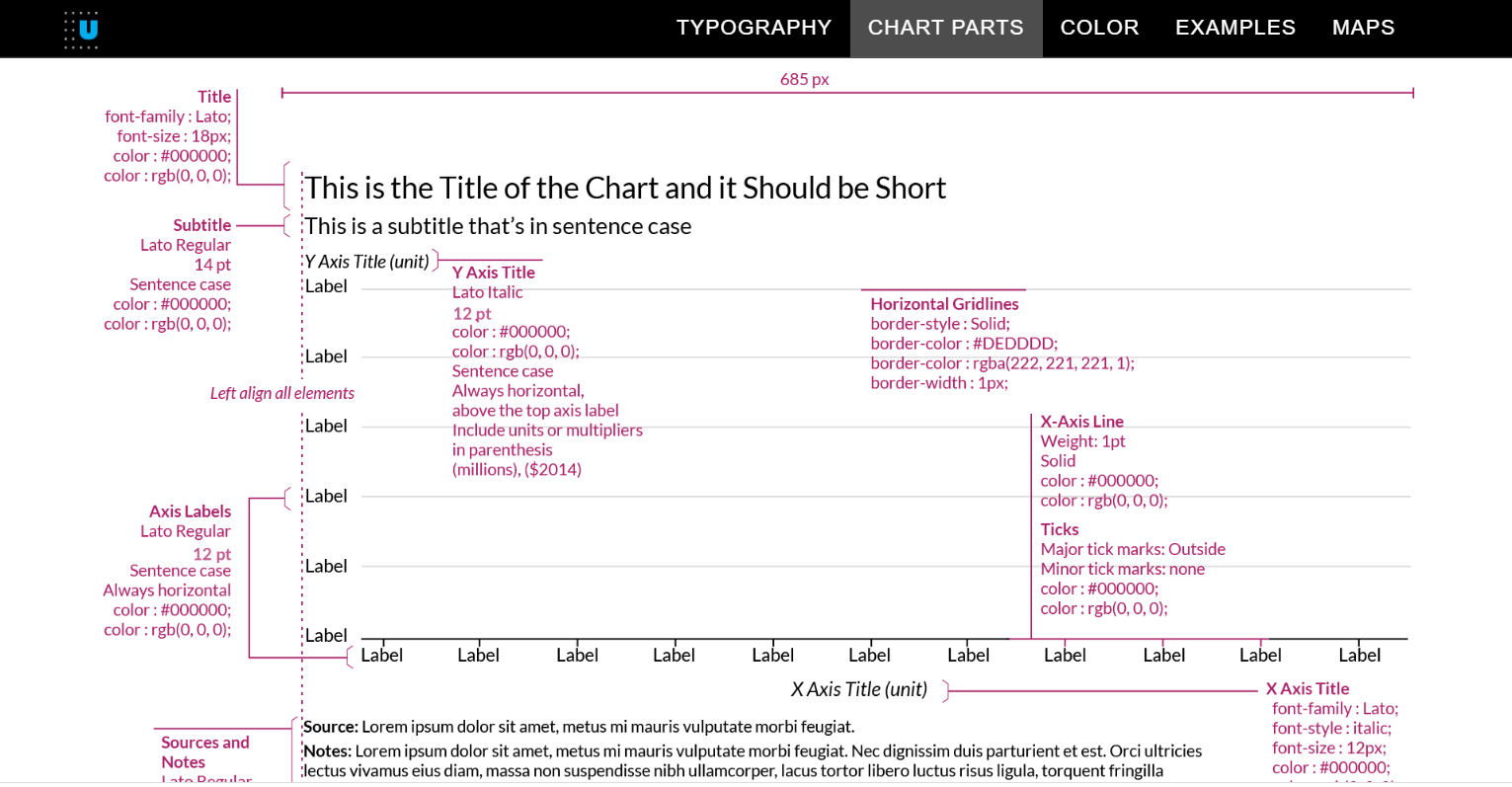


Tener definidos colores, fuentes y tamaños es una ayudadota. El theme sale de volada:
#Cargar la fuente desde mi Windows
windowsFonts(`Lato` = windowsFont("Lato"))
# Crear theme
# Inspirado en el styleguide del Urban Institute
# https://urbaninstitute.github.io/graphics-styleguide/
theme_fb <- theme(
#Esto pone blanco el titulo , los ejes, etc
plot.background = element_rect(fill = '#FFFFFF', colour = '#FFFFFF'),
#Esto pone blanco el panel de la gráfica, es decir, sobre lo que van los bubbles
panel.background = element_rect(fill="#FFFFFF",color="#FFFFFF"),
panel.grid.minor = element_blank(),
panel.grid.major.y = element_line(color="#DEDDDD"),
panel.grid.major.x = element_blank(),
text = element_text(#color = "#1db954",
family="Lato"),
# limpiar la gráfica
axis.line = element_line(colour="#FFFFFF"),
#axis.title=element_blank(),
axis.text=element_text(family="Lato",
size=12),
axis.ticks=element_blank(),
axis.title.x = element_text( margin=margin(10,0,0,0),
family="Lato",
size=12,
color="#0D1F2D"
),
axis.title.y = element_text( margin=margin(0,15,0,0),
family="Lato",
size=12,
color="#0D1F2D"
),
# ajustar titulos y notas
plot.title = element_text(family="Lato",
size=18,
margin=margin(0,0,15,0),
hjust = 0, #align left
color="#0D1F2D"),
plot.subtitle = element_text(size=14,
family="Lato",
hjust = 0, #align left
margin=margin(0,0,25,0),
color="#0D1F2D"),
plot.caption = element_text(
color="#0D1F2D",
family="Lato",
size=11,
hjust = 0 #align left
),
legend.position = "none",
#para los titulos del facet_wrap
strip.text.x = element_text(size=12, face="bold"),
complete=FALSE
)
#pequeño truco para crear el caption con negritas y que puedo reusar en las gráficas
my_caption <- expression(paste(bold("Fuente:"), " Datos proporcionados por Facebook para el usuario ", bold("nerudista")))
Los invito a intenten replicar alguna de las guías que vienen en la lista que está arriba y vean como sus visualizaciones empiezan a verse más profesionales. Después pueden crearse las propias que reflejen su estilo de visualización.
Preparando los datos
Para poder trabajar con análisis de texto necesitamos crear un corpus. Es decir, un conjunto de documentos a analizar. En nuestro caso no basta solo con pegar los dos documentos (posts y comments) sino que hay que preprocesarlos para:
- Crear una columna que nos diga si es un post o un comment (se me olvidó hacerlo en el Python pasado).
- Quitar las stopwords. Es decir, las palabras que se repiten mucho y no nos sirven en el análisis (articulos, pronombres, conjunciones, etc).
- Quitar números y puntuaciones.
La primera parte es sencilla y podemos sacarla con este código:
# cargar archivos
data_comments <- read_csv("./Datos/misComentarios.csv")
data_posts <- read_csv("./Datos/misPosts.csv")
# Crear columan "tipo"
data_comments <- data_comments %>% mutate(tipo = "Comentario")
data_posts <- data_posts%>% mutate(tipo = "Post")
data <- rbind(data_comments, data_posts)
# cargar stopwords en español
stop_words <- tm::stopwords(kind="es")
#cargar palabras que no eliminó el paquete tm::stopwords
my_stop_words <- c("si","p","d","así","tan","!","¡","=","$",
"esposa","de","que","a","with","to","ps","made","nocroprc")
#Unir los dos vectores de stop words
final_stop_words <- c(stop_words,my_stop_words)
Tengan presente la variable my_stop_words. Más adelante vamos a ver porqué tuve que crearla.
Creando corpus, tokens y wordclouds
Quanteda es un paquete en R que nos permite crear corpus, tokenizar y crear algunas gráficas. Otro paquete es tm pero ese lo vamos a utilizar más adelante.
Nota: Una de las cosas que más se me complican es saber a qué #BibliotecaNoLibreria corresponde cada comando. Para intentar que no les pase, voy a usar cada comando mencionando previamente la biblioteca, por ejemplo
tm::stopwords. Si solo pusierastopwordstambién jalaría pero la idea es que sepan de donde viene cada comando.
Convertir el dataframe en un corpus es bastante sencillo. Basta con este comando:
corp_comments <- quanteda::corpus(data$Comment)
Lo que sigue es tokenizar (convertir cada palabra en un objeto que puede analizarse) y después quitar las palabras que no nos sirven. La premisa es que las palabras que más se repiten como los artículos, pronombres, preposiciones; son las que menos aportan al análisis. Las palabras que se repiten menos son las más características de nuestros textos y las que más nos pueden ayudar al análisis. Por eso es importante quitar la paja desde el principio.
En mi primera ejecución quité los stopwords que vienen por default en tm::stopwords pero cuando vi los tokens me di cuenta que había muchas que no servían en para mi analisis en particular. A lo que voy es que deben entrar a ensuciarse con los datos antes de empezar a hacer cosas bonitas. Si conoces tus datos, les puedes sacar más jugo.
Después de varias iteraciones saqué la lista de palabras que quería quitar y es entonces cuando creé la variable my_stop_words. Esta la que acabé usando para crear la que usé al final: final_stop_words
Con Quanteda podemos tokenizar y hacer limpieza en el mismo comando. Esto va a crear un objeto donde cada registro va a ser un token. Después necesitamos crear una Document Feature Matrix (dfm) que es otro tipo de objeto donde cada token se convierte en una “columna” en vez de un registro.
El código es muy simple:
#creo un corpus con QUANTEDA con los comentarios
corp_comments <- quanteda::corpus(data$Comment)
# voy a tokenizar cada post
tok_comments <- quanteda::tokens(corp_comments,
remove_numbers = TRUE,
remove_punct = TRUE) %>%
tokens_remove(pattern = final_stop_words,
valuetype = 'fixed')
# ahora voy a crear una matrix dfm
dfmat_comments <- quanteda::dfm(tok_comments,remove_punct = TRUE)
Con el dfm podemos ya aplicar varios comandos para sacar las frecuencias de tokens, analisis de sentimientos o para crear nubes de palabras, entre otras cosas.
Empecemos con una nube de palabras:
set.seed(132)
quanteda::textplot_wordcloud(dfmat_comments,
color = rev(RColorBrewer::brewer.pal(10, "RdBu")),
max_words = 100,
random_order =FALSE)

Y podemos ver que soy una persona muy agradecida y que mando muchos abrazos, jeje. Hay por ahí algunos hashtags que me recuerdan que use una app durante un tiempo para publicar fotos.
Ahora vamos a repetir el proceso, con unas pequeñas variantes, pero ahora con tidytext.
El principio es el mismo: vamos a leer el data frame, hacerle limpieza de dígitos y puntuaciones y después tokenizarlo.
##### TIDYTEXT #####
#Voy a limpiar un poco la base para estandarizarla
data.limpia <- data %>%
mutate(Comment = iconv (Comment,"UTF-8", "ASCII//TRANSLIT")) %>% # QUITA ACENTOS Y CARAC. ESPECIALES
mutate(Comment = tolower(Comment)) %>%
mutate(Comment = str_squish(Comment)) %>%
mutate(Comment = str_remove_all(Comment,"[[:punct:]]") ) %>%
mutate(Comment = str_remove_all(Comment,"[[:digit:]]") )
Para tokenizar tidytext nos deja usar varias opciones:
- word , para tokenizar por palabra.
- sencence , para tokenizar por frase.
- ngram, para tokenizar por agrupaciones de n-gramas (un bigrama son dos palabras juntas, 4-grama son 4 palabras y así sucesivamente).
Para variar un poco voy a ocupar la opción de 2-gramas y crear una wordcloud con la biblioteca del mismo nombre:
#Ahora a tokenizar por palabra
tidy.tokens.word <- data.limpia %>%
tidytext::unnest_tokens(word,Comment)
#Ahora a tokenizar por oracion
#Da casi lo mismo que la data.limpia.
tidy.tokens.sentence <- data.limpia %>%
unnest_tokens(sentence, Comment, token = "sentences")
#Ahora por n-gramas
tidy.tokens.ngram <- data.limpia %>%
unnest_tokens(ngram, Comment, token = "ngrams", n = 2)
cuenta.ngramas <- tidy.tokens.ngram %>%
count(ngram) %>%
arrange(-n) %>%
#dplyr::filter(!ngram %in% tm::stopwords(kind="es")) %>%
dplyr::filter(!ngram %in% final_stop_words) %>%
dplyr::filter(nchar(ngram)> 0)
#Visualizar ngramas
cuenta.ngramas %>%
with(wordcloud::wordcloud(ngram,
n,
max.words = 40,
random.order = FALSE,
colors = rev(brewer.pal(5,"Paired"))))

En el repo viene el código que tienen que agregar para que le den buen tamaño a la imagen y no se les corten palabras.
Analisis de sentimientos
Aprovechando que tenemos recién creado el objeto tidy.tokens.word, que contiene tokens por palabra, intentemos hacer algo de análisis de sentimientos. Para eso necesitamos usar un diccionario de palabras. Los más usadons son Affin, NRC y Bing. Cada uno tiene sus caracteristicas especiales. Si los buscan en Google hay buenos artículos que mencionan sus diferencias.
Vamos a ocupar el diccionario AFFIN en español que ronda por la internet para ligarlo con cada uno de los tokens que tenemos. El diccionario lo que tiene es algo así:
| Palabra | Puntuacion | Word |
|---|---|---|
| abandona | -2 | abandons |
| abandonado | -2 | abandoned |
| abandonar | -2 | abandon |
Las palabras están puntuadas del -5 al 5.
Vamos a unir el diccionario para luego agrupar por tipo de publicacion (post o comment), sumar la puntuacion de cada agrupación y hacer una gráfica para estrenar el theme que no hemos usado.
# ahora con afinn
afinn.esp <- read_csv("./datos/lexico_afinn.en.es.csv",
locale=locale(encoding = "LATIN1"))
fb.affin.esp <- tidy.tokens.word %>%
filter(!word %in% final_stop_words) %>%
inner_join(afinn.esp,
by = c("word" = "Palabra" )) %>%
distinct(word, .keep_all = TRUE)
#graficar
fb.affin.esp %>%
group_by(tipo) %>%
summarise( neto = sum(Puntuacion)) %>%
ggplot( aes(x=tipo,
y=neto,
fill = tipo))+
geom_col()+
geom_text( aes(x=tipo,y=neto,label = neto),
nudge_y = 8,
family="Lato",
fontface="bold",
size=4.5
)+
labs(title="Sentimiento por Tipo de Publicación",
subtitle = "Calificación Obtenida Usando AFFIN",
caption = my_caption,
y= "",
x="")+
scale_fill_manual(values = c("#0a4c6a","#cfe8f3"))+
theme_fb
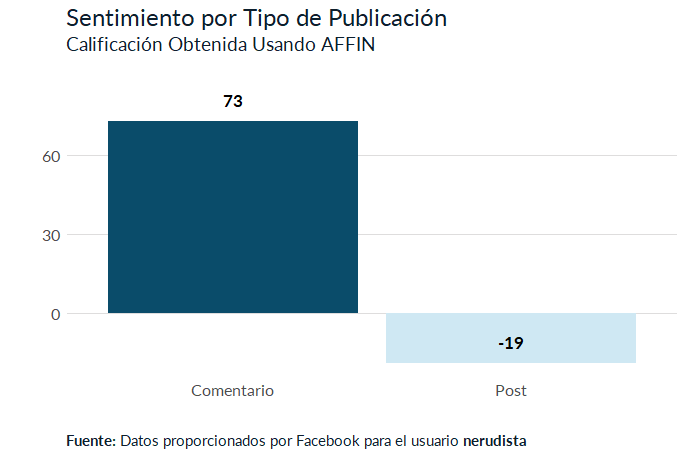
Lo que se puede ver es que mis respuestas a posts de otros solían ser bastante positivos. Todo lo contrario a cuando hacá post propios. Tiene sentido para mí porque usualmente escribo para criticar algo o expresar mi rechazo hacia algo principalmente político (mi Twitter es un gran ejemplo de eso) mientras que solía responder a muchas publicaciones de cumpleaños de mis amigos. Si recordamos las salidas de ambas wordclouds podemos ver que lo que más decía era “gracias”, “abrazo” y “felicidades”.
¿En serio una tercera parte?
Sí. Porque nos falta jugar con diccionarios NRC, calcular el TF-IDF y encontrar tópicos usando LDA.
Espero este blog les hay aparecido interesante y les den ganas de ir a pedir sus datos y jugar con ellos. Siéntanse libres de contactarme en mi Twitter @nerudista si se les ofrece algo.
Así que no se desesperen. La próxima semana se viene la última y nos vamos. ***
¿Qué te pareció la nota? Mandanos un tuit a @tacosdedatos o a @nerudista o envianos un correo a ✉️ sugerencias@tacosdedatos.com. Y recuerda que puedes subscribirte a nuestro boletín semanal aquí debajo.
Subscríbete a 🌮 tacos de datos | Aprende visualización de datos en español.
Recibe las mejores publicaciones directamente a tu caja de entrada