Dueño de mis datos - Capítulo Facebook - Parte III
La última entrega de la serie de Text Mining con mis datos de Facebook
Bienvenidos al último post de esta serie. Si quieren ver cómo obtuvimos los datos o cómo creamos los corpus con los que vamos a trabajar hoy, denle click en los enlaces.
Recordemos de qué se trata este guateque:
… vamos a jugar con todos los posteos que hice en Facebook y todos los comentarios que puse a posteos de otras personas. Aprovechando el gran curso de Text Mining que @jmtoral nos dio durante la cuarentena, vamos a analizar mis textos e intentar encontrar algunas cosas interesantes. Al final, y porque nos gusta mucho, haremos gráficas y más gráficas.
Una wordcloud más usando AFINN
El post pasado acabamos usando el diccionario AFINN para determinar que tan positivos o negativos, en lo general, eran mis posts y mis comments.
Para acabar de usar este diccionario esta vez vamos a crear una nube de palabras donde pongamos de un color las palabras positivas y en otro color las negativas. Para esto vamos a tener que crear una nueva columna que nos podrá el sentimiento como positivo si la palabra tiene una puntuación de entre 1 y 5. Si está entre -1 y -5, la pondrá como negativa.
Por último, usaremos la función comparison.cloud para crear la gráfica y asignar los colores:
png("graficas/comparacion_cloud.png", width = 1000, height = 1000, res=200)
affin.count <- fb.affin.esp %>%
mutate(sentimiento = dplyr::case_when(
Puntuacion < 0 ~ "Negativo",
Puntuacion > 0 ~ "Positivo"
)) %>%
count(tipo,sentimiento,word) %>%
arrange(-n) %>%
reshape2::acast(word ~ sentimiento, fill = 0, value.var = "n") %>%
wordcloud::comparison.cloud(colors = c("#db2b27", "#12719e"),
random.order = FALSE,
scale=c(1.5,.5),
title.size = 2,
max.words = 400)
dev.off()

Usando el Diccionario NRC
Otro diccionario muy usado en el diccionario NRC. A diferencia del AFINN donde cada palabra tenía una calificación numérica, en NRC la palabra puede ser clasificada como positiva o negativa (sin escala númerica) pero además puede entrar dentro de alguna de estas emociones:
- anger - enojo
- anticipation - expectación
- disgust - disgusto
- fear - miedo
- joy - alegría
- sadness - tristeza
- surprise - sorpresa
- trust - seguridad
Para usar este diccionario tenemos que usar la #BibliotecaNoLibreria syuzhet. Empezemos utilizando nuestro data frame inicial (data$Comment) y después agrupemos por sentimiento y emoción para tener los totales de cada una:
# Sentiment analysis con syuzhet
# Aplico NRC a mis posts y comments
fb_sentimientos_nrc <- syuzhet::get_nrc_sentiment(data$Comment , language = "spanish")
df_fb_sentimientos_nrc <- fb_sentimientos_nrc %>%
dplyr::summarise_all(funs(sum)) %>%
rowid_to_column("id") %>%
pivot_longer(-id, names_to = "sentimiento", values_to = "count")
Ya con el objeto df_fb_sentimientos_nrc podemos empezar a crear visualizaciones. Mi primer acercamiento fue una de barras pero de esas ya hicimos. Así que me aventuré a hacer un treemap que no habíamos hecho en post anteriores. Como sólo la haremos por emociones filtraré los sentimientos (positivo, negativo):
# treemap
df_fb_sentimientos_nrc %>%
filter(!sentimiento %in% c('positive','negative')) %>%
treemap(
index="sentimiento",
vSize="count",
type="index",
fontsize.labels=c(12),
fontsize.title = 18,
palette = "Blues",
title="Sentimientos en Post y Comments",
fontfamily.title = "Lato",
fontfamily.labels = "Lato",
border.col = "#191414"
)+
theme_fb

La verdad no encontré muchas opciones para aplicar el theme a la gráfica ya que la función treemap no es parte de ggplot.
Lo que podemos ver de la gráfica es que en su mayoría mis palabras expresan confianza y alegría. El disgusto, la tristeza, el miedo y el enojo están presentes pero no en gran cantidad.
Quiero destacar que esta gráfica no es la mejor para poder comparar. Nuestro cerebro es malo para diferenciar áreas. Solo la hice para usar la función y poder generar algo que no hayamos hecho antes.
¿Qué se les ocurre para poder comparar mejor?
Ya para terminar, hagamos una gráfica de barras con el número de palabras por sentimiento:
## grafica con positivo y negativo
BarPositiveNegative <- df_fb_sentimientos_nrc %>%
filter(sentimiento %in% c('positive','negative')) %>%
ggplot( ) +
geom_col(aes(x= reorder(sentimiento,count),
y= count,
fill = sentimiento))+
labs(title = "Clasificación de Palabras Por Sentimiento ",
caption = my_caption ,
y = "Número de Palabras",
x= "")+
scale_fill_manual(values=c("#db2b27", "#12719e"))+
scale_x_discrete(labels=c("Negativas","Positivas")) +
theme_fb;BarPositiveNegative
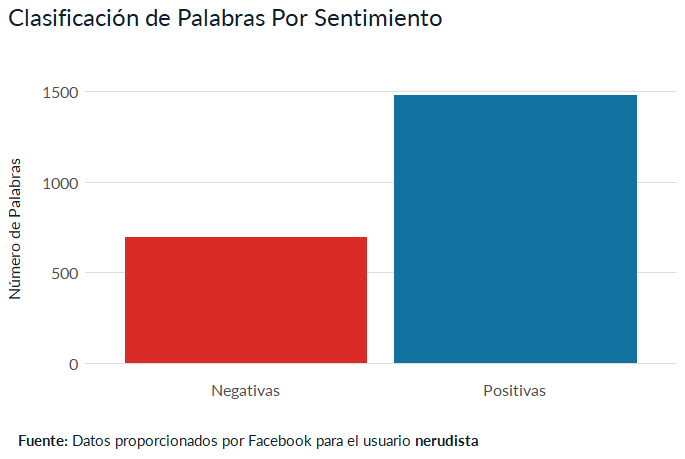
Esta gráfica confirma lo que veíamos en el treemap. Solía usar muchas más palabras positivas que negativas. Casi el triple.
TF-IDF
Imagínense que tenemos un documento, por ejemplo, acerca de Michael Jordan (¿ya vieron “The Last Dance”?) y que nos ponemos a analizarlo. ¿Cómo podríamos saber si se trata acerca de ganar un campeonato, sobre sus apuestas, Space Jam o su paso por el beisbol? Ahí es cuando entra es el TF : Term Frequency. Si un término se repite mucho es muy probable que nos de una buena pista acerca del contenido. Por ejemplo, si la palabra “Murray” es top 10 en apariciones, es muy probable que hable de Space Jam, si la palabra que más aparece es “swing” es muy probable que hable de beisbol. Para poder obtener un buen TF es importantísimo haber limpiado ya los datos, haberles quitado stopwords y otros términos que no nos sean de utilidad.
¿Pero qué pasa si no tenemos sólo un documento sino más de cien? Ese corpus puede tener diferentes temas y el TF puede resultar no tan eficiente. Ahí es cuando entra el TF-IDF: Term Frequency-Inverse Document Frequency. Antes de seguir, intentaré resumir la parte del IDF. Básicamente es qué tanto aparece ese término en los demás documentos del corpus. La fórmula tiene más chiste que eso, incluso usa logaritmos, pero no es mi intención entrar en la matemática. Ahora bien, el TF-IDF usa las dos métricas que acabamos de ver y nos dice el peso de un término dentro de un documento.
 http://ccdoc-tecnicasrecuperacioninformacion.blogspot.com/2012/11/frecuencias-y-pesos-de-los-terminos-de.html
http://ccdoc-tecnicasrecuperacioninformacion.blogspot.com/2012/11/frecuencias-y-pesos-de-los-terminos-de.html
Todo este show es para que tengamos una idea de lo que vamos a intentar obtener y cómo lo vamos a interpretar. Tirar comandos es fácil pero tirarlos con sentido y saber interpretarlo es lo que cuenta.
La biblioteca que usaremos es tidytext y vamos a reutilizar uno de los objetos que creamos en el post anterior
#Necesito que ya esté tokenizado los post y los comments
# voy a usar el tidy.tokens.word
#para que los DF no me de exponentes en en los resultados.
options(scipen=99)
#Calcular del tf_idf de un plumazo
tfidf <- tidy.tokens.word %>%
filter(!word %in% final_stop_words) %>%
count(word,tipo) %>%
tidytext::bind_tf_idf(word,tipo,n)
Lo que intento hacer al agregar el tipo es encontrar las palabras con más peso dependiento el tipo de publicación: post o comment.
Vamos a crear una gráfica de barras para averiguar de qué hablé más en cada caso:
#primero creo los labels para los titulos del facet_wrap
labels <- c(comment = "Comentario", post = "Post")
tfidf %>%
group_by(tipo) %>%
arrange(-tf_idf) %>%
top_n(5) %>%
#ungroup() %>%
ggplot(aes( x = reorder(word,tf_idf),
y = tf_idf,
fill = tipo))+
geom_col(show.legend = FALSE)+
scale_fill_manual(values = c("#0a4c6a","#cfe8f3"))+
facet_wrap( ~ tipo,scales = "free",
labeller =labeller(tipo=labels))+
coord_flip()+
labs(title="Palabras más Representativas por Tipo de Publicación",
subtitle = "Ranking obtenido por TF_IDF",
caption = my_caption,
y= "",
x="")+
theme_fb
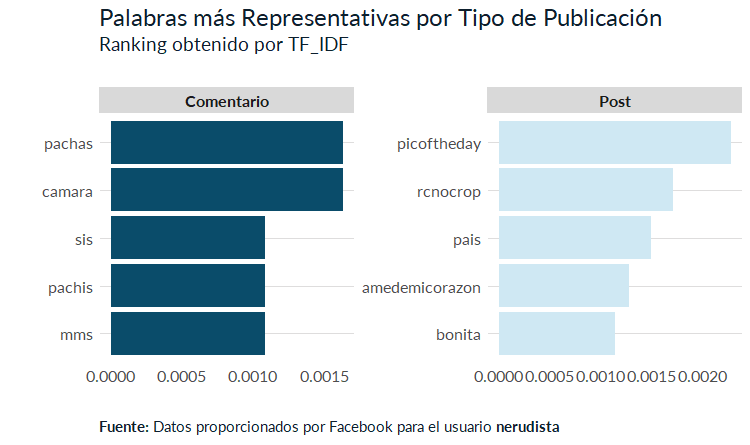
Intentemos sacar algunas inferencias:
- En los comentarios “pachas” y “pachis, los sobrenombres de una amiga, son muy relevantes.
- Por otro lado, Es muy característico de mis posts las etiquetas “picoftheday”, “rcnocrop” y “amedemicorazon”. Lo cual me cuadra perfecto pues mi FB estaba ligado a mi Instagram dentro de la aplicación rcnocrop.
- En los comentarios que hacía a otras personas era tan “ofensivo” como para poner “mms” pero no como para poner “mames”. Grosero, grosero pero no tanto.
LDA o Latient Dirichlet Allocation para los cuates.
Ya para terminar juguemos un poco con LDA. Este es un método de topic modelling que nos permite identificar tópicos dentro de una serie de documentos. Haciendo un símil muy burdo, es como encontrar clústeres dentro del corpus.
Para echarlo andar necesitamos crear una DTM:_ Document Term Matrix_ que vamos a obtener con la biblioteca tm. Además, nosotros tenemos que definir cuántos clústers o grupos queremos que cree el algoritmo.
Veamos el código:
# Crear un corpus
# lee el vector y lo convierte en un corpus
corpus.fb <- tm::Corpus(VectorSource(data$Comment))
corpus.fb <- tm::tm_map(corpus.fb, removeWords, stopwords("es"))
corpus.fb <- tm::tm_map(corpus.fb, removePunctuation)
corpus.fb <- tm::tm_map(corpus.fb, removeNumbers)
dtm.fb <- tm::DocumentTermMatrix(corpus.fb)
# Aplicaré este truco porque sin él suelo
# tener errores por filas vacías.
rowTotals <- apply(dtm.fb , 1, sum)
dtm.fb <- dtm.fb[rowTotals>0,]
# ahora sí, el LDA para 4 clústeres
bd.lda <- topicmodels::LDA(dtm.fb,k=4,control=list(seed=1234))
El objeto bd_lda es un vector que no puedo usar para gráficar. Tengo que pasarlo a un dataframe con el comando tidy de tidytext. Este tiene dos opciones para el argumento matrix:
betapara obtener la probabilidad de tópicos por palabragammapara obtener la probabilidad de tópicos por documento
Para nuestra gráfica utilizaremos beta:
bd.topics <- tidytext::tidy(bd.lda, matrix="beta") #Prob por topico por palabra
# Va la gráfica
top_terminos %>%
mutate(term = reorder_within(term,beta,topic)) %>%
ggplot(aes(term,
beta,
fill=factor(topic)))+
geom_col()+
facet_wrap(~ factor(topic), scales = "free")+
coord_flip()+
scale_y_continuous(labels = scales::percent_format())+
scale_fill_manual(values = c("#1696d2","#ec008b","#fdbf11","#5c5859"))+
scale_x_reordered()+ # necesita el mutate de arriba. Quita el __1, __2 que éste pone.
labs(title = "Probabilidad de palabras por tópico",
caption = my_caption ,
y = "Porcentaje LDA ",
x= "Palabra")+
#scale_fill_manual(values=c("#db2b27", "#55b748","fdbf11","898F9C"))+
theme_fb
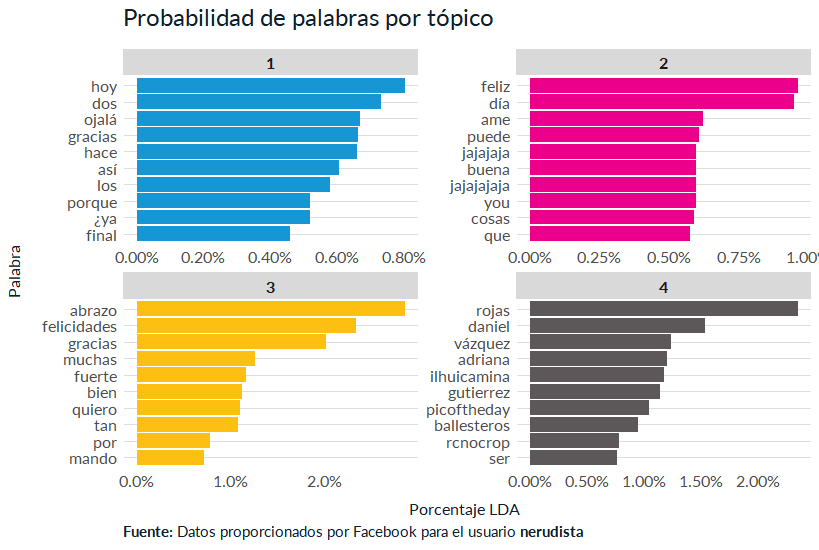
Lo que reconozco de la gráfica:
- Los porcentajes más altos están en lso tópicos 3 y 4. No se dejen llevar por el 2%. Es un muy buen número considerando el número total de documentos.
- En el tópico 3 están muchas felicitaciones y abrazos.
- En el tópico 4 están las publicaciones que metí desde Instagram y donde mencionaba a amigos con los que intereactuaba mucho.
- En el tópico dos hay risas y felicitaciones.
- El tópico 1 me muestra que no hice una limpieza correcta de datos. Hay muchos stopword ahí que no limpié.
Esto último fue un poco intencional para que vean como el algoritmo puede traer basura si no lo alimentamos bien. Como dice el adagio: garbage in, garbage out
¿Y qué sigue?
P’acabar pronto, que se vayan a este repo y que intenten replicar lo que hicimos pero con sus datos. Como hay datos sensibles sólo les dejé los archivos de post y comments con cuatro o cinco registros. La idea es que pidan sus datos y sigan el camino de esta serie para que puedan replicar. Si se atoran, estoy siempre atento a responder en @nerudista
Como lo he mencionado en los post previos: piérdanle el miedo a analizar datos y a graficarlos. Además, los datos de sus usuarios que andan en la red son valiosos. Sean responsables con ellos.
Espero que esta serie les haya desportado la cosquilla de empezar a practicar algo nuevo. No tienen porqué dedicarse a esto. Yo no lo hago pero jugarle es enriquecedor. Además, en estos tiempos de crisis ninguna nueva habilidad está de sobra.
Gracias por llegar hasta aquí. BTW, #QuédateEnCasa
¿Qué te pareció la nota? Mandanos un tuit a @tacosdedatos o a @nerudista o envianos un correo a ✉️ sugerencias@tacosdedatos.com. Y recuerda que puedes subscribirte a nuestro boletín semanal aquí debajo.
Subscríbete a 🌮 tacos de datos | Aprende visualización de datos en español.
Recibe las mejores publicaciones directamente a tu caja de entrada