Dueño de mis datos - Capítulo Spotify
Tal vez porque soy un poco paranoico o porque trabajo en una empresa que va codo a codo con algunos gigantes de la industria pero el caso es que decidí ir a Facebook, Twitter, Google y Spotify a pedir los datos que tienen de mí.
En este post vamos a jugar un poco con ggplot y con los datos de reproducciones que tuve en el último año. Empezaremos viendo en dónde pueden pedir la información que tienen de ustedes y después haremos unas tres gráficas con algunas #BibliotecasNoLibrerias que me aventuré a conocer.
Recuerden que estos posts son para principiantes hechos por otro principiante. Si consideran que algo del código se pudo hacer mejor, denle fork al repo y manden su pull request para que todos podamos aprender algo nuevo.
Dicho esto, a darle que es mole de olla.
Consiguiendo los datos
Lo primero es ir a la página https://www.spotify.com/mx/account/privacy/. Después de autenticarse con su usuario y contraseña les va a aparecer esto:

Si van bajando sobre esa página van a encontrar la sección “Descargar tus datos”:

Si leen como atención, cosa que yo no hice, se darán cuenta que les van a dar el historial de streaming del último año y sus datos de facturación así como sus playlist entre otras cosas.
Sigan el proceso que viene descrito en un unos pocos días, en mi caso fueron 3, les llegará un enlace para que puedan descargar su información. El .zip que me enviaron contenía los siguientes archivos:
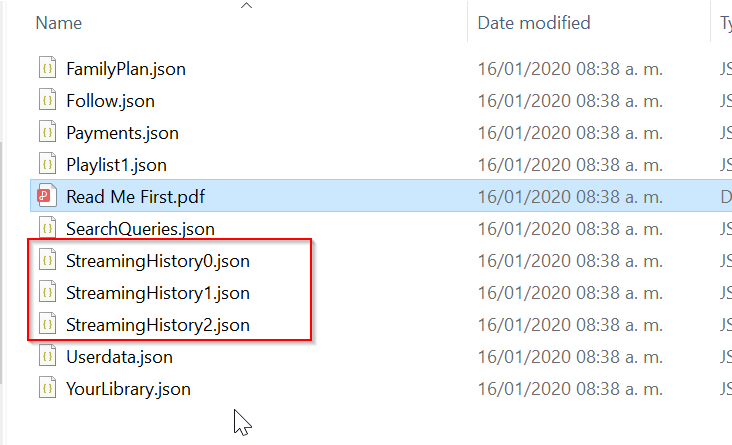
Por favor lean el archivo “Read Me First.pdf”. Dentro viene un enlace donde encontraran el diccionario de datos de cada archivo recibido. Para este ejercicio sólo vamos a trabajar con los archivos encerrados en el recuadro rojo. Esos archivos son mi historial de reproducción del último año.
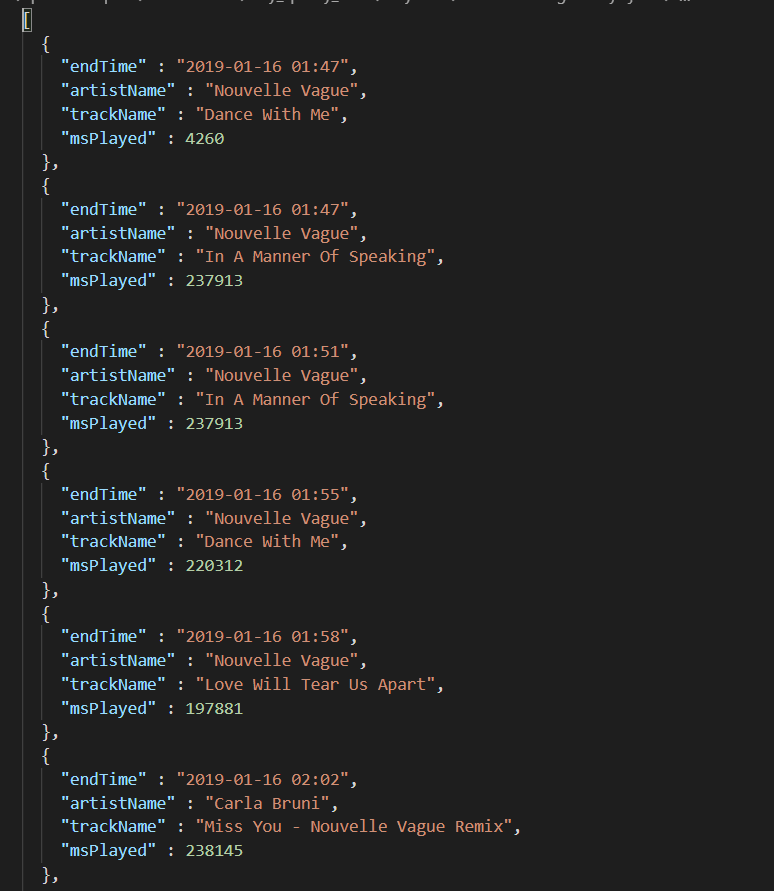
El contenido lo pueden ver en esta imagen:
Haciendo bocetos
Del ejercicio de los Pats aprendí que lo mejor era primero hacer bocetos para después tirarme un clavado al código.
Este es el primer boceto que hice:
El resto del documento lo pueden ver el repo dentro del archivo MySpotifyIdeas.pdf
Creando mi theme
Crear un theme ayuda a simplificar el código que tenemos que escribir para cada gráfica. Para este caso conseguí los códigos de colores que usa Spotify en su aplicación y el font más parecido al que usaban en su versión anterior. El de la nueva ya tenía costo así que por economía nos veremos oldies but goodies
Este es el código para el theme que utilizaremos:
#theme
#colors
# 1db954, 1ed760, ffffff, 191414
theme_spoty <- theme(
#Esto pone negro el titulo , los ejes, etc
plot.background = element_rect(fill = '#191414', colour = '#191414'),
#Esto pone negro el panel de la gráfica, es decir, sobre lo que van los bubbles
panel.background = element_rect(fill="#191414",color="#191414"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
text = element_text(color = "#1db954",
family="Gotham" #esta es la fuente que instalé en mi lap
),
# limpiar la gráfica
axis.line = element_line(colour="#191414"),
axis.title=element_blank(),
axis.text=element_blank(),
axis.ticks=element_blank(),
# ajustar titulos y notas
plot.title = element_text(size=32,
color="#1db954"),
plot.subtitle = element_text(size=20,
color="#1db954"),
plot.caption = element_text(
color="#1db954",
face="italic",
size=13
),
complete=FALSE
)
Esta vez aprendí la diferencia entre el plot.background y panel.background. El panel es el espacio donde se pintan las figuras y el plot abarca el espacio del título, los ejes y el caption.
Fuera de eso, lo demás es limpieza de ejes y asignar fuentes y colores. Anímense a cambiar los valores para que vean como cambia su gráfica.
Importando los datos
Como recibí tres archivos con los datos de streaming tenemos que importarlos y después unirlos. Eso se hace bien fácil con:
#importar json como dataframe
df0 <- fromJSON("./Data/StreamingHistory0.json")
df1 <- fromJSON("./Data/StreamingHistory1.json")
df2 <- fromJSON("./Data/StreamingHistory2.json")
#Unir los dataframes
data <- rbind(df0,df1,df2)
#Cargar la fuente desde mi Windows
windowsFonts(`Gotham` = windowsFont("Gotham"))
Al final cargo la fuente que voy a utilizar para las gráficas. Como tengo Windows sólo descargué la fuente de un sitio de internet y luego hice drag and drop a mi pantalla de Font Settings. Una vez instalada la fuente en Windows ya puedo usarla en R con ese comando.
Historical Bubble Chart
No sé si se llame así pero me gusta el nombre. Lo que vamos a hacer es graficar verticalmente bubbles que tendran como encoding el mes de reproducción en la posición y el tamaño para los minutos de reproducción. Es decir, algo así:

Antes de ver el código intentemos desmenuzar la gráfica para saber qué es lo que tenemos que hacer.
Cada circulo representa el artista que más escuché en el mes. Esto significa que tengo que agrupar el tiempo reproducido de cada canción por artista y por mes y luego sacar el top 1 de cada mes. Algo así:
dfArtistaMes <- data %>%
group_by(mesAño,artistName)%>%
summarise(minutosMes= round((sum(minPlayed)))) %>%
top_n(1) #me da el top1 de cada grupo creado arriba
Intentemos pensar en las capas que necesitamos para crear la gráfica:
- Una capa para las burbujas. Estan van ordenadas en el mismo punto X pero ordenadas cronológicamente, de arriba hacia abajo, en el eje Y.
- Una capa para los textos de la derecha: mes-año.
- Una capa para los textos de la derecha: artista más escuchado por mes.
- Una capa para los textos de la derecha: minutos.
- Una capa para la línea blanca que atraviesa las bolitas para dar idea de continuidad (conque aplicando Teoría Gestalt eh?).
El código para crear estas capas fue:
plotArtistaMes <-ggplot(data=dfArtistaMes,
aes( x=1,
y=reorder(mesAño, desc(mesAño)) #ordenar ascendente el mesAño
)
)+
geom_point( aes( #Capa 1
size=minutosMes,
color=artistName),
show.legend = FALSE,
alpha = 1
) +
geom_text(aes(x=1.06,label=mesAño), #Capa 2
color="#FFFFFF",
family="Gotham",
size=6,
hjust="left")+
geom_text(aes(x=.94, #Capa 3
label=artistName,
color=artistName),
family="Gotham",
size=6,
show.legend = FALSE,
hjust="right")+
geom_text(aes(x=.94, label=paste(minutosMes,"m")), #Capa 4
hjust="right",
size=6,
color="#FFFFFF",
family="Gotham",
vjust=1.8)+
geom_line(data=data.frame(x=c(1,1),y=c(1,13)), #Capa 5
aes(x=x, y=y),
alpha=0.4,
size=.85,
color="#FFFFFF",
linetype = "dotted")+
scale_x_discrete(limits=c(1))+
scale_radius(range = c(4, 26))+
scale_color_brewer(palette="Dark2")+
labs(title="Mi Spotify en el Último Año",
subtitle="Minutos escuchados por artista",
caption="Hecho por @nerudista con datos de Spotify") +
theme(
plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5)
)+
theme_spoty ; plotArtistaMes
Para esta gráfica no busqué en internet cómo hacerla sino que me imaginé cómo armarla desde cero. Si usteden encuentran una mejor opción, ¡compartanla!.
Lo que hice fue poner todas las burbujas en el valor x=1 y para las capas de los textos le resté, o sumé, algunas centésimas para ponerlas a la derecha o la izquierda. Después ya es cosa de poner título, subtítulo y caption. Centrar los primeros dos y aplicar el theme.
Bueno, ya que estamos con burbujas intentemos hacer algo más coqueto.
Circle Packing para mostrar cada canción escuchada
Desde hacía buen rato había querido hacer un treemap pero en burbujas. Circle Packing le llaman.
Esta es la gráfica que haremos:

Lo que intento visualizar es qué canciones escuché por más tiempo durante el último año. Para esto voy a poner el tamaño de la burbuja como encoding y el color será diferente por cada canción.
Esta vez tenemos que agrupar no por artista ni por mes sino por canción en todo el año:
dfCanciones <- data %>%
group_by(artistName,trackName) %>%
summarise(min=sum(minPlayed))%>%
filter (min > 5)
Vamos a necesitar una nueva #BibliotecasNoLibreria para crear esta visualización:
#install.packages("packcircles")
library("packcircles")
Ya con el data frame agrupado por cancion, vamos a meter la canción (trackName) a la función circleProgressiveLayout para que nos cree un nuevo dataframe con la posición x,y y el radio de cada burbuja:
| x | y | radio |
|---|---|---|
| -1.34224959 | 0.00000000 | 1.342250 |
| 1.95766469 | 0.00000000 | 1.957665 |
| … | … | … |
| 5.05310636 | 4.81689588 | 2.509851 |
Después hay que meter ese nuevo data frame a la función circleLayoutVertices:
# los npoints dicen las caras de la figura 3-triangulo, 4-cuadrado
# con el 50 ya se parece a un círculo
dat.gg <- circleLayoutVertices(packing, npoints=50)
Lo que queda es ya crear la gráfica:
plotSingleBubble <- ggplot()+
# Make the bubbles
geom_polygon(data=dat.gg, aes(x,
y,
group=id,
colour = "black",
alpha = 0.6,
fill=as.factor(id)
)
) +
scale_size_continuous(range = c(1,5)) +
labs(title="Un Universo de Música",
subtitle="Minutos de reproducción por canción ",
caption="Hecho por @nerudista con datos de Spotify") +
scale_color_brewer(palette="Dark2")+
#theme_void()+
theme_spoty+
theme(legend.position="none") +
coord_equal(); plotSingleBubble
Poquito código y queda algo bonito. Sin embargo no me dice qué canción escuché más ni cuántos minutos escuché cada uno. No pintamos texto sobre las burbujas porque o no cabe o es tanto texto que tapa las figuras.
¿Y si cuando pase el mouse me dijera qué canción es y cuánto la escuché? Eso ya sería hacer algo interactivo. Y pues …
Circle Packing interactivo
Primero vamos a importar la biblioteca para la parte interactiva. Luego toca crear una columna nueva en el data frame con el texto que queremos desplegar:
#install.packages("ggiraph")
library(ggiraph)
# Add a column with the text you want to display for each bubble:
dfSimpleBubble$text <- paste("Canción: ",dfSimpleBubble$dfCanciones.trackName, "\n", "Min:", dfSimpleBubble$dfCanciones.min)
Lo que sigue es crear de nuevo la gráfica de burbujas pero agregando el tooltip con la línea:
tooltip= dfSimpleBubble$text[id]:
plotSingleBubbleInter <- ggplot()+
geom_polygon_interactive(data=dat.gg,
aes(x,y,
group=id,
fill=as.factor(id),
tooltip= dfSimpleBubble$text[id],
family="Gotham",
data_id = id),
colour = "black", alpha = 0.6)+
theme_spoty +
scale_color_brewer(palette="Dark2")+
theme(legend.position="none") +
labs(title="Un Universo de Música",
subtitle="Minutos de reproducción por canción ",
caption="Hecho por @nerudista con datos de Spotify") +
coord_equal()
widg <- ggiraph(ggobj = plotSingleBubbleInter, width_svg = 6, height_svg = 9)
Ya con la gráfica construido hay que pasarla por ggiraph para que cree la parte interactiva. El resultado de esto es un archivo html con su respectiva carpeta que contiene los archivos necesarios para crear la visualización web. Si revisan el código van a darse cuenta que usa javascript por debajo para construir la visualización. ¡Un pasito más cerca de D3!
Vean nomás qué chulada queda:
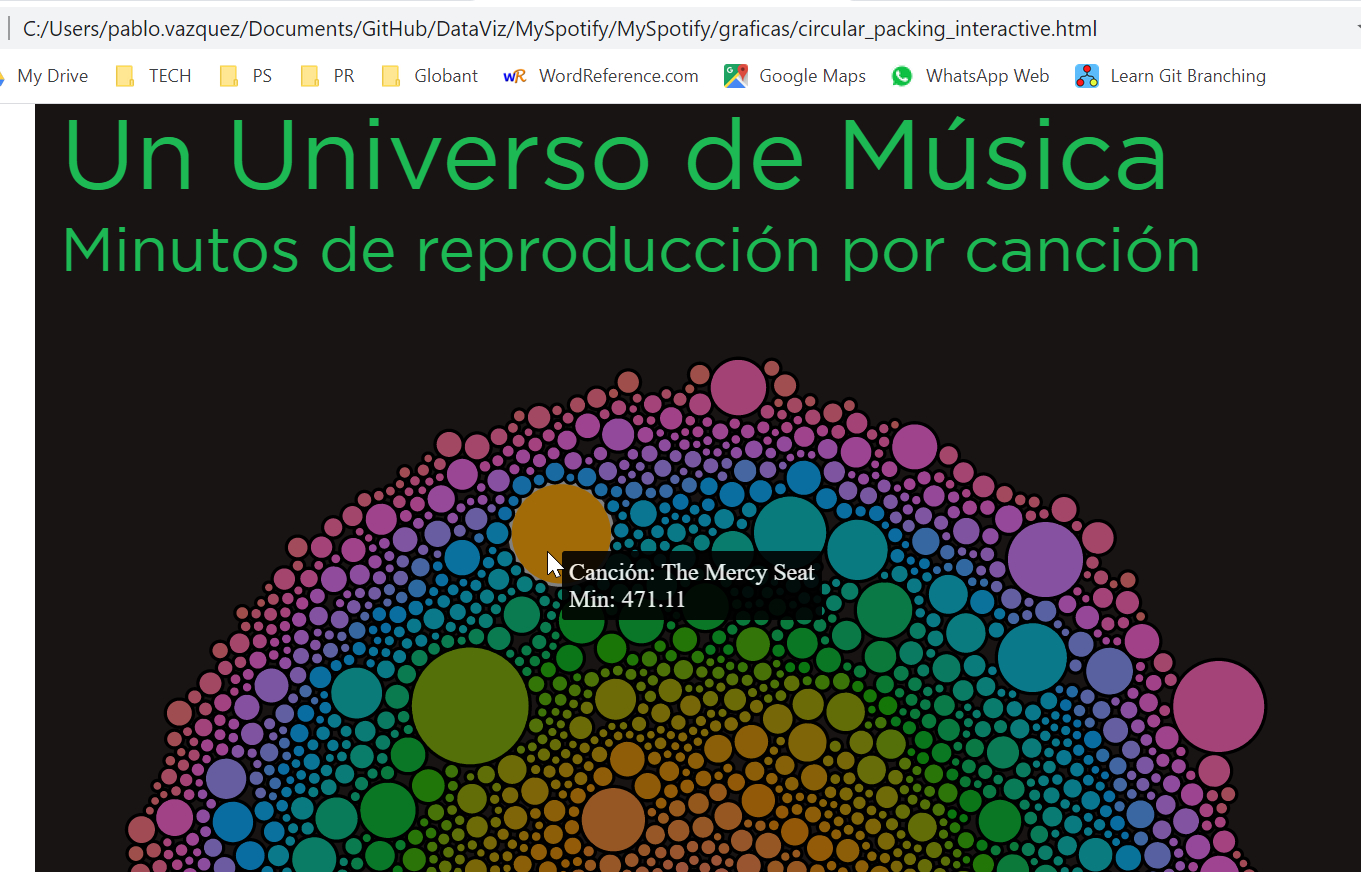
De mis pendientes quedan poder poner color por artista y no por canción. Tengo que agarrarle más la onda a las funciones de los vértices para poder tener en el data frame alguna variable por artista que me deje hacer el fill por ese nuevo campo y no por id.
Lollipops
Y ya para acabar con los geom_points() haremos una grafica de ¿paleta?. No sé cómo le digan en español pero en inglés les dicen lollipop.
Empecemos viendo el resultado final para desmenuzarla de nuevo:
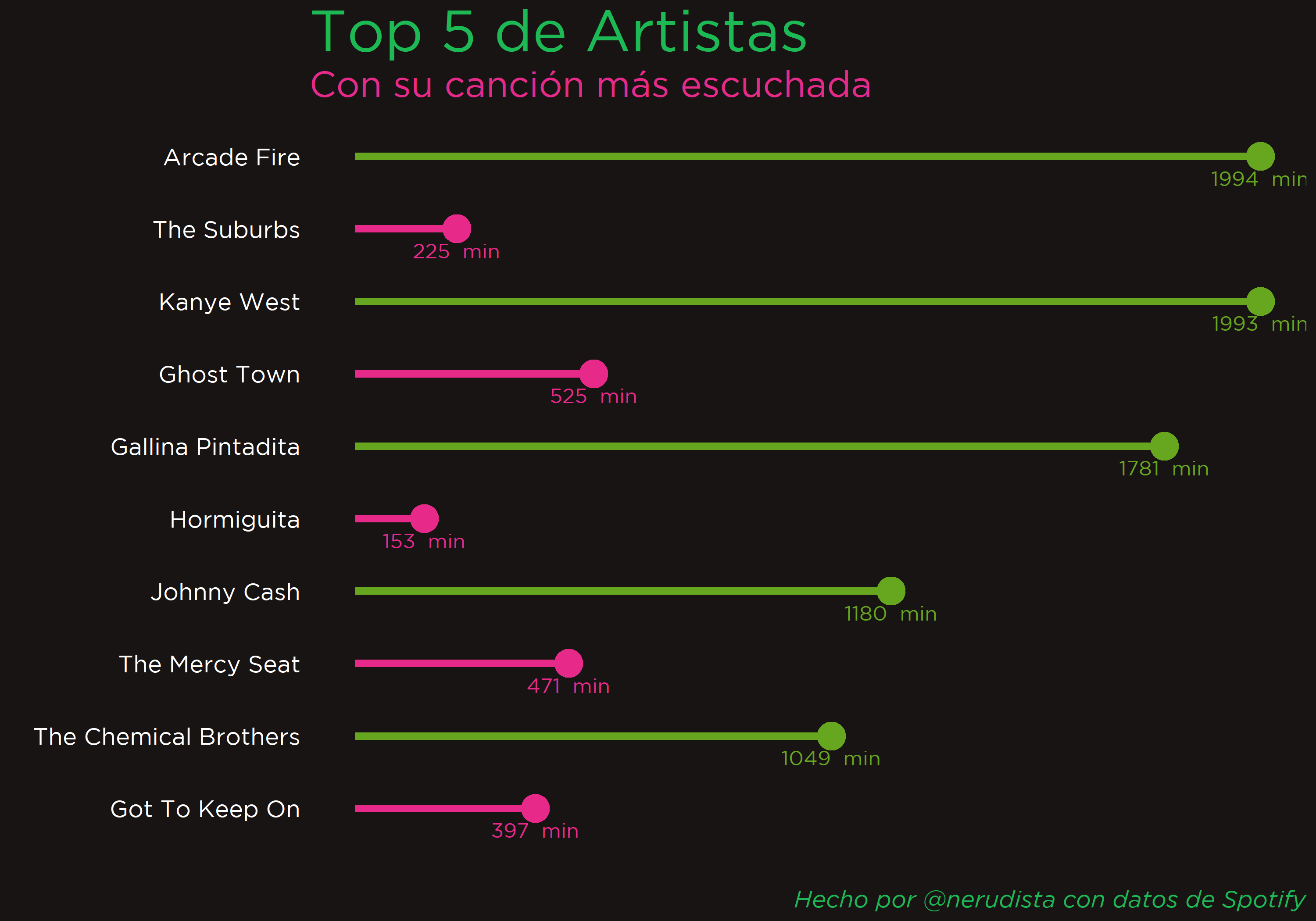
La gráfica muestra los 5 artistas más escuchados e inmediatamente después muestra qué canción, de ese artista, fue la más escuchada. Ojo aquí, no es el top 5 de artistas y el top 5 de canciones. Es el top 5 de artistas con su respectiva canción más reproducida. Este pequeño detalle me hizo darle varias vueltas a la solución.
Lo primero es crear los data frames para tener los artistas y las canciones:
#Crear data frame con el tiempo total por cada canción junto con el artista.
#Necesito el artista para filtrar más adelante.
dfCanciones <- data %>%
group_by(artistName,trackName) %>%
summarise(min=sum(minPlayed))%>%
filter (min > 5)
# Crear df el top n de artistas por minutos reproducidos en el año
dfArtistaAnio <- data%>%
group_by(artistName)%>%
summarise(min=sum(minPlayed)) %>%
top_n(5)%>% # de una vez me quedo con el top 5
arrange(min) # ordeno ya encarrerado el ratón
Ya con ambos dataframes voy a crear uno nuevo, basado en dfCanciones, donde esté agrupado por artistName. No le voy a poner que sumarise nada sólo quiero la estructura del group by para aplicarla en el siguiente paso.
Sigue crear el df dfTopCanciones que es el resultado de tomar el top 1 del df artistas para finalmente hacerle merge al df dfArtistaAnio. Al final nos quedan los 5 artistas más escuchados con su respectiva canción.
Sé que suena enredado pero solo son 3 comandos. Muévanle a esos tres para que vean que resultados diferentes les dan para que tenga cierta lógica:
# crear un df con el group by solo por artistName
artistas <- dfCanciones %>% group_by(artistName)
# filtrar el df artistas tomando el registro con más minutos. Va inverso porque no hay max_rank()
# sino min_rank(). Solo tomo un row: el más alto
dfTopCanciones <- filter(artistas, min_rank(desc(min)) <= 1 )
# hago un join entre el df dfArtistaAnio y dfTopCanciones por artistName
# así solo me quedan los top artistas con su canción más escuchada
dfCancionesArtistasTop <- merge(x=dfArtistaAnio, y=dfTopCanciones, by="artistName", all.x = TRUE)
La salida del último df es:
| artistName | min.X | trackName | min.Y |
|---|---|---|---|
| Arcade Fire | 1993.59 | The Suburbs | 224.74 |
| Gallina Pintadita | 1781.42 | Hormiguita | 153.22 |
Hasta ahí parece que vamos bien pero ¿cómo usamos esta salida para graficar? Podría usar dos capas donde en el primer aes(x= ?) use artistName y en la otra el trackName. Sin embargo, cuando junte las capas el orden se me rompe.
Como todo en esta vida hay más de una forma de solucionar las cosas y la que se me ocurrió fue generar esta salida:
| item | min | type |
|---|---|---|
| Arcade Fire | 1993.59 | A |
| Gallina Pintadita | 1781.42 | A |
| … | … | … |
| The Suburbs | 224.74 | C |
Donde el ìtem es la canción o el artista, min los minutos reproducidos y en type “C” si es canción y “A” si es artista. Esta variable es importante para poder hacer formato condicional dentro de la misma capa. Con este df ya no necesito hacer dos capas sino una sola condicionando la salida por el tipo de item.
Este es el código para crear la salida que buscamos:
dfTemp1 <- data.frame( item = dfCancionesArtistasTop$artistName,
min = dfCancionesArtistasTop$min.x,
type = "A")%>% arrange(-min)
# manualmente pongo el orden en que quiero que aparezcan los artistas
dfTemp1$order <- c(1,3,5,7,9)
dfTemp2 <- data.frame( item = dfCancionesArtistasTop$trackName,
min = dfCancionesArtistasTop$min.y,
type = "C")
# manualmente pongo el orden en que quiero que aparezcan las canciones
dfTemp2$order <- c(2,6,8,4,10)
dfCancionesArtistasTopList=rbind(dfTemp1,dfTemp2)
Noten que también creamos una columna con el orden en específico en que queremos que aparezcan los items. Como eran pocos registros lo hice manual. Si fueran mcuhos más, toca pensar como hacerlo en automático.
Intentemos dibujar la gráfica desde la gramática de gráficos:
- Una capa para las líneas del lollipop.
- Una capa para el círculo de la paleta.
- Una capa para los textos (minutos escuchados).
- LA capa de título, subtítulo, etc.
Con esto en mente es más fácil saber qué construir:
#ahora a pintar la gráfica
plotTop5 <- ggplot(data=dfCancionesArtistasTopList,
aes(x=item,
y=min
))+
geom_segment(data=dfCancionesArtistasTopList ,
aes(x=reorder(item,-order),
xend=item,
y=0,
yend=min
),
color=ifelse(dfCancionesArtistasTopList$type=="A","#67A61F","#E72A8A"),
size=2
)+
geom_point(
color=ifelse(dfCancionesArtistasTopList$type=="A","#67A61F","#E72A8A"),
size=7
)+
geom_text(aes(label=paste(round(min,0)," min")),
color=ifelse(dfCancionesArtistasTopList$type=="A","#67A61F","#E72A8A"),
size=4,
#color="#FFFFFF",
family="Gotham",
nudge_x = -.3)+
coord_flip()+
scale_color_brewer(palette="Dark2")+
ylab("")+
xlab("")+
theme(legend.position="none") +
labs(title="Top 5 de Artistas",
subtitle="Con su canción más escuchada",
caption="Hecho por @nerudista con datos de Spotify") +
theme(
text = element_text(color = "#1db954",
family="Gotham"
),
#Esto pone negro el titulo , los ejes, etc
plot.background = element_rect(fill = '#191414', colour = '#191414'),
#Esto pone negro el panel de la gráfica, es decir, sobre lo que van los lollipops
panel.background = element_rect(fill="#191414",color="#191414"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
plot.title = element_text(size=32,
color="#1db954"),
plot.subtitle = element_text(size=20,
color="#E72A8A"),
plot.caption = element_text(
color="#1db954",
face="italic",
size=13
),
axis.text=element_text(family = "Gotham",
size=13,
color="#FFFFFF"),
axis.ticks=element_blank(),
axis.text.x = element_blank(),
);plotTop5
Noten dos cosas:
- El uso el
ifelsecon la variabletypeque creamos. Podemos jugar con el color dependiendo de si es canción o artista. - No apliqué mi theme porque en él desaparezco las leyendas de los ejes y aquí los necesito para mostrar el nombre de la canción y el artista sobre el eje Y. Además, quería mostrarles la diferencia entre un
+theme_spotyy tooooodo lo que tuve que poner para arreglar la gráfica. ¿Ven porqué están chidos los themes?
Comentarios finales
Después del ejercicio de los Pats intenté hacer cosas nuevas usando bibliotecas nuevas. No le tengan miedo. Anímense. Poco a poco irán saliendo cosas mejores. La cosa es no dejar de aprender.
Por otro lado, los aliento a ir pos sus datos a todas las plataformas en las que estén inscritos. Son sus datos y tienen derecho a saber qué conocen de ustedes. En Spotify no encontré nada especial pero en otros servicios sí me he ido para atrás con lo que han colectado de mí. Cultivemos una cultura de la responsabilidad de los datos. Son parte de nustra vida.
Por último, les recuerdo que este año Github está duplicando las donaciones que le hagan a @tacosdedatos. Con esa lana se puede pagar un chorro de cosas para mantener el sitio arriba y hasta para rifar uno que otro libro, si se junta la lana. Un dolar al mes es menos que una cerveza al día. ¿Ah, verdad?
Recursos
Para esta entrada usé muchísimo la página Data to Viz. Ahí van a encontrar chorro de ejemplos en R, Python y hasta en otras herramientas.
El repo con el código está en:
https://github.com/nerudista/DataViz/tree/master/MySpotify
Enren a verlo poque hay código que no puse en el blog y que en necesario para que las gráficas funcionen. Ya saben, cosa de economía para que el blog no se haga eterno y lo boten a media lectura.
¿Qué te pareció la nota? Mandanos un tuit a @tacosdedatos o a @nerudista o envianos un correo a ✉️ sugerencias@tacosdedatos.com. Y recuerda que puedes subscribirte a nuestro boletín semanal aquí debajo.
Subscríbete a 🌮 tacos de datos | Aprende visualización de datos en español.
Recibe las mejores publicaciones directamente a tu caja de entrada