Dueño de mis datos - Capítulo Facebook
En mi entrada anterior les platiqué acerca de cómo fui a pedir la información que tienen de mí las redes sociales que suelo, o solía, utilizar.
Es esta nueva serie vamos a jugar con todos los posteos que hice en Facebook y todos los comentarios que puse a posteos de otras personas. Aprovechando el gran curso de Text Mining que @jmtoral nos dio durante la cuarentena, vamos a analizar mis textos e intentar encontrar algunas cosas interesantes. Al final, y porque nos gusta mucho, haremos gráficas y más gráficas.
¡A darle átomos!

Consiguiendo los datos
Tus datos son precísamente eso: TUYOS. Así que cualquier servicio que uses te los debería dar cuando los pidas.
Eso hice hace unos meses pero, por descuidado, no guardé las capturas de pantalla del proceso. Y es que, además, pedir mis datos fue la última cosa que hice antes de borrar definitivamente la cuenta que hice por allá en 2008.
Pero no todo está perdido. En esta página vienen los pasos a seguir.
Para que se den una idea de cuánto guardan de nosotros les diré que recibí 26 folders donde en cada uno pueden venir uno o varios JSON.
Aquí algunos de ellos:
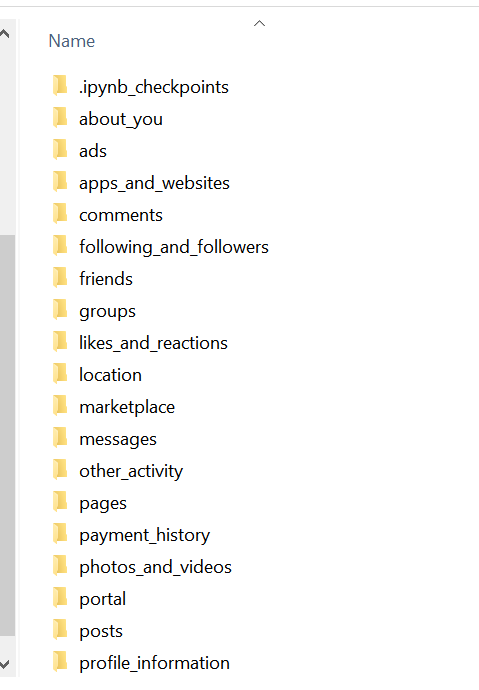
Para este análisis sólo usaremos los que vienen en los folders posts y comments:

Preparando los datos
Una ventaja de los JSON es que no tienen una estructura fija. Pueden contener tantos elementos como queramos. Son súper flexibles. Sin embargo, no son lo ideal para nuestro análisis.
Dado que haremos análisis de textos sólo nos interesan las cosas que escribí. Para este pequeño análisis podemos descartar muchos de los campos que vienen ahí. Vamos a quedarnos con tres: la hora de la publicación, el título de la publicación y el texto que escribí.
Empecemos con los más fáciles: los comentarios a otros posts. EL JSON viene de esta manera:
{
"comments": [
{
"timestamp": 1483030841,
"data": [
{
"comment": {
"timestamp": 1483030841,
"comment": "Avisen!! Vivo a la vuelta :p",
"author": "Pablo Quetzalc\u00c3\u00b3atl"
}
}
],
"title": "Pablo Quetzalc\u00c3\u00b3atl coment\u00c3\u00b3 la publicaci\u00c3\u00b3n de Nata TP."
},
{
"timestamp": 1476976208,
"data": [
{
"comment": {
"timestamp": 1476976208,
"comment": "\u00c2\u00bfC\u00c3\u00b3mo no lo pens\u00c3\u00a9 antes?",
"author": "Pablo Quetzalc\u00c3\u00b3atl"
}
}
],
"title": "Pablo Quetzalc\u00c3\u00b3atl coment\u00c3\u00b3 la publicaci\u00c3\u00b3n de SuFa Rojbas."
}
]
}
Lo primero que vemos es que los caracteres latinos vienen con algún enconding que tenemos que arreglar. Spoiler alert: sufriremos por novatos.
Si analizamos bien el archivo, podemos ver que el comment que queremos está :
- En la llave
comment - Dentro del diccionario
comment - Dentro de la lista
data - Dentro de la lista `comments
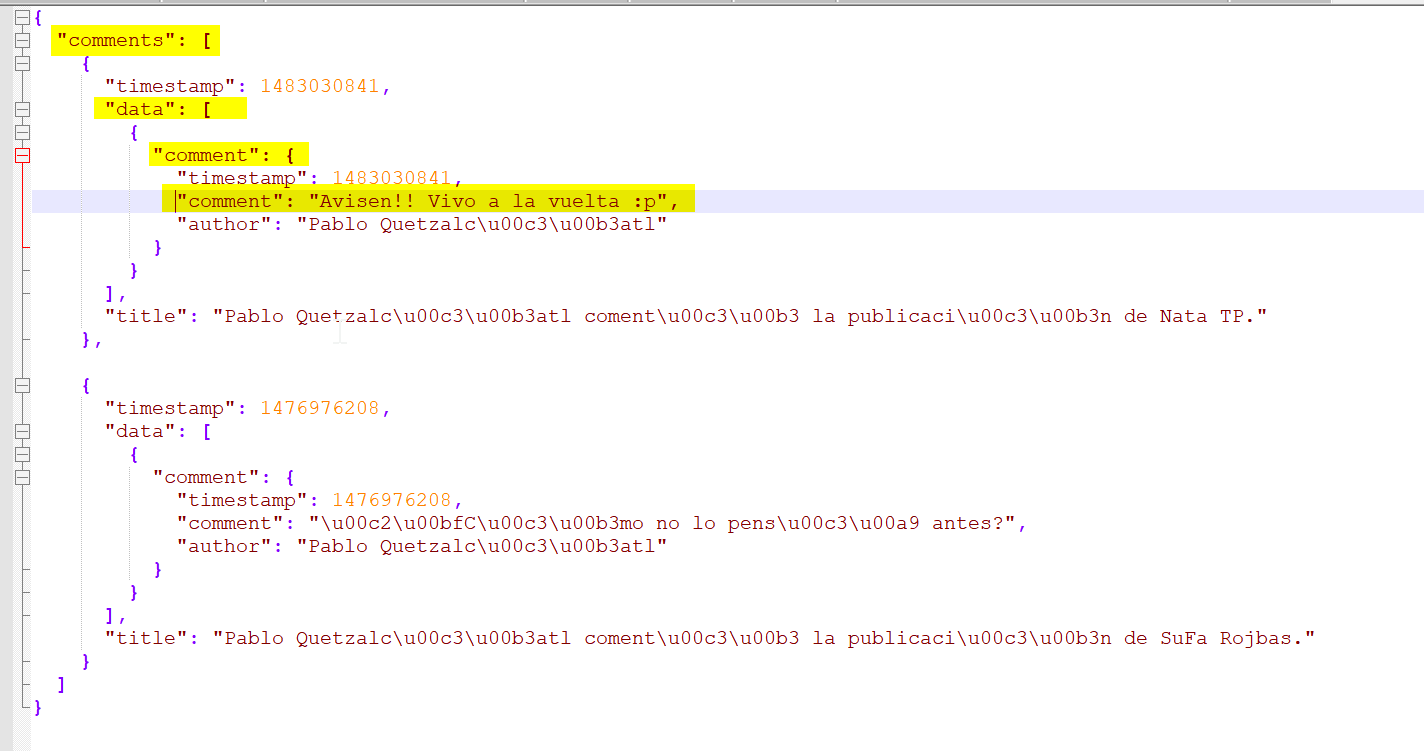
Con este código nos quedamos con los tres campos que queremos:
# Creo una lista para quedarme la lista final de campos
mis_comentarios=[]
# comments son diccionarios dentro de la lista data
comments = data['comments']
# itero sobre la lista para obtener los datos de cada post
for count,element in enumerate(comments):
try:
#lista para un row
#print(count)
comentario=[]
if element['data']:
j = element['data']
l = j[0]['comment']
#print (element['title'])
comentario.append(l['timestamp'])
comentario.append(element['title'].encode('latin1').decode('utf8'))
comentario.append(l['comment'].encode('latin1').decode('utf8'))
else:
#print("error")
comentario.append(element['timestamp'])
comentario.append(element['title'].encode('latin1').decode('utf8'))
comentario.append('')
#print (comentario)
mis_comentarios.append(comentario)
except:
#print ("error in : " + str(element))
pass
with open ("./datos/misComentarios.csv", 'w',encoding='utf-8',newline='') as file:
writer = csv.writer(file,
quoting=csv.QUOTE_NONNUMERIC)
writer.writerow(["Timestamp", "Title", "Comment"])
writer.writerows(mis_comentarios)
Siendo honestos exageré un poco. Yo sufrí mucho pero ustedes no tienen porqué hacerlo. La solución al encoding está en esta línea .encode('latin1').decode('utf8').
Para mayor explicación pueden ver este hilo de Twitter que hice cuando batallé con esto.
Ahora vámonos con los posts:
[
{
"timestamp": 1509378754,
"attachments": [
{
"data": [
{
"external_context": {
"name": "The Strokes - I Can't Win - Listen on Deezer",
"source": "Deezer",
"url": "http://www.deezer.com/en/track/15591112"
}
}
]
}
],
"data": [
],
"title": "Pablo Quetzalc\u00c3\u00b3atl escuch\u00c3\u00b3 The Strokes - I Can't Win - Listen on Deezer de The Strokes - Listen on Deezer | Music Streaming en Deezer."
},
{
"timestamp": 1499345371,
"attachments": [
{
"data": [
{
"external_context": {
"name": "Cuentos Completos I",
"source": "Goodreads",
"url": "http://www.goodreads.com/book/show/1058650.Cuentos_Completos_I"
}
}
]
}
],
"data": [
],
"title": "Pablo Quetzalc\u00c3\u00b3atl made progress with a book on Goodreads."
},
{
"timestamp": 1476742550,
"data": [
{
"post": "Que no se diga que los programadores, testers y BA's son solo unos gorditos buena onda.\nBusco alguien que est\u00c3\u00a9 interesado en que lo entrene para un triatl\u00c3\u00b3n. \nNo experience required. For free. \nAnybody?"
}
],
"title": "Pablo Quetzalc\u00c3\u00b3atl public\u00c3\u00b3 en Globant MX Market && Social."
},
{
"timestamp": 1475510192,
"data": [
{
"post": "Tarde pero seguro.\nFeliz cumplea\u00c3\u00b1os Sara."
}
],
"title": "Pablo Quetzalc\u00c3\u00b3atl escribi\u00c3\u00b3 en la biograf\u00c3\u00ada de Sara Lozano."
}
]
Aquí la cosa ya se pone más coqueta porque las estructuras cambian. Los primeros dos elementos son publicaciones que dos aplicaciones hicieron en mi nombre (y que nunca les presté atención) y los últimos dos son publicaciones reales.
Miren la diferencia:
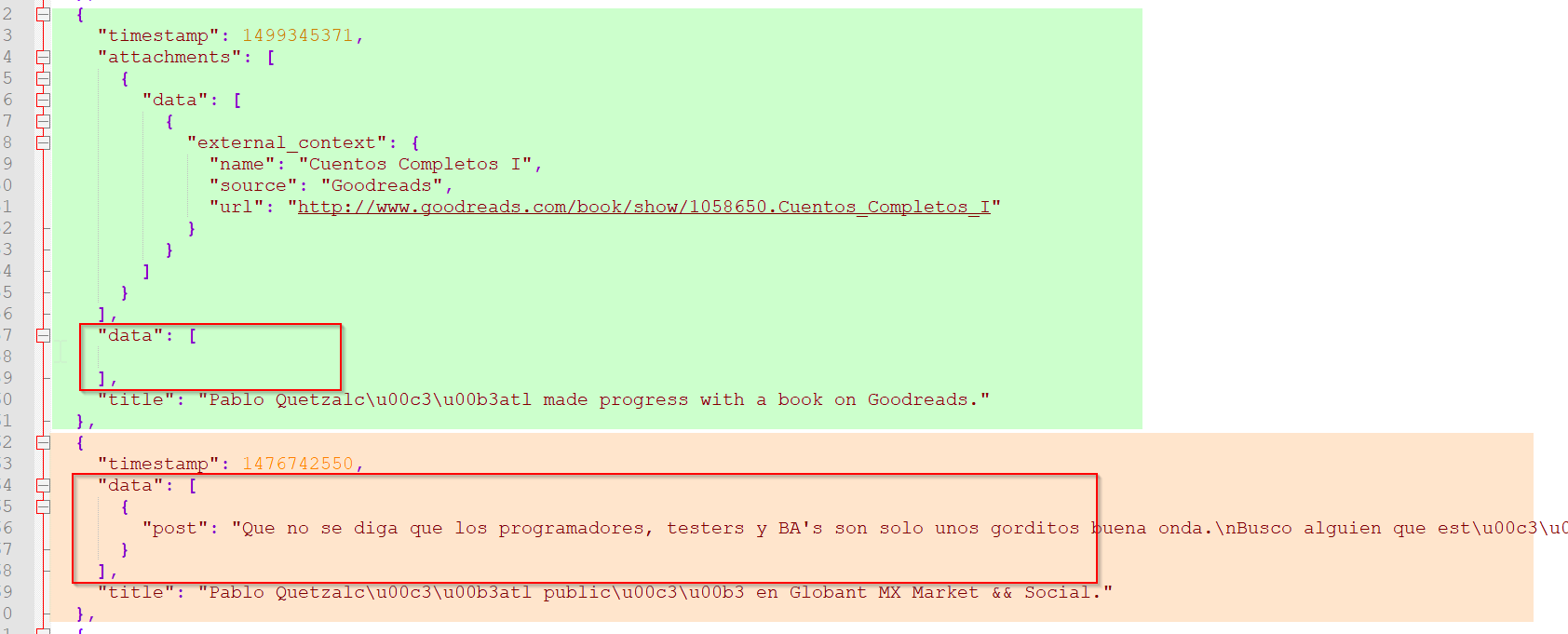
Aunque la estructura cambia hay una lista que se repite. En el caso de las aplicaciones externas queda en blanco y en mis publicaciones hay una llave post. Con eso ya podemos jugar.
# Creo una lista para quedarme la lista final de campos
list_posts=[]
error_list=[]
# El archivo es una lista de diccionarios. Voy a iterar en ella
for count, element in enumerate(posts):
try:
list_single_post =[]
#asignar el title
if element.get("title"):
title = element['title'].encode('latin1').decode('utf8')
else:
title = "No Title"
if element.get("timestamp"):
time_stamp = element['timestamp']
# asignar el post
if element.get('data'):
data_key = element.get('data')
#print (type(data_key))
for key in data_key:
if key.get('post') :
#print(key)
post = str(key.get('post')).encode('latin1').decode('utf8')
list_single_post.append(time_stamp)
list_single_post.append(title)
list_single_post.append(post)
list_posts.append(list_single_post)
except Exception as e: # work on python 3.x
print(e)
with open ("./datos/misPosts.csv", 'w',encoding='utf-8',newline='') as file:
writer = csv.writer(file,
quoting=csv.QUOTE_NONNUMERIC)
writer.writerow(["Timestamp", "Title", "Comment"])
writer.writerows(list_posts)
¡Y listo! Ya tenemos dos archivos CSV con los datos que vamos a ocupar.
¿Y los bocetos?
Esta vez rompí mi regla de crear bocetos en papel y es que me enfoqué más en poder hacer los análisis y no tenía una idea de qué me iba a encontrar y por ende no sabía qué y cómo graficar.
Disculpen la omisión. Les prometo que lo que se viene lo compensa.
Let’s pause
Vamos a dejar aquí esta primera parte para que aquí dejemos lo que hicimos en Python y en la siguiente nos vamos a mover a R que es donde haremos el text-mining.
El repo con el código está en mi Github
Entren a verlo poque hay código que no puse en el blog y que vale la pena que le echen ojo.
Si les gustó, ¡comenten! Ya sea aquí o en Twitter. El comment es el alimento del blogger.
¿Qué te pareció la nota? Mandanos un tuit a @tacosdedatos o a @nerudista o envianos un correo a ✉️ sugerencias@tacosdedatos.com. Y recuerda que puedes subscribirte a nuestro boletín semanal aquí debajo.
Subscríbete a 🌮 tacos de datos | Aprende visualización de datos en español.
Recibe las mejores publicaciones directamente a tu caja de entrada