Primeros pasos con ggplot (R) y Altair (Python) - Parte II
Bienvenidos a la segunda y última parte de mi aventura por ggplot y Altair
En la entrada anterior les platiqué acerca del reto que decidí hacer (analizar castigos a favor y en contra de la #PatsNation), de cómo hice el dataset y de cómo hice las dos primeras gráficas de barras: una dodge o grouped y una stack.
En este artículo vamos a hacer otras cuantas gráficas, haré mis conclusiones y dejaré algunas recomendaciones para que no pasen el camino de espinas que me tocó recorrer.
Tenga para que se entretenga.
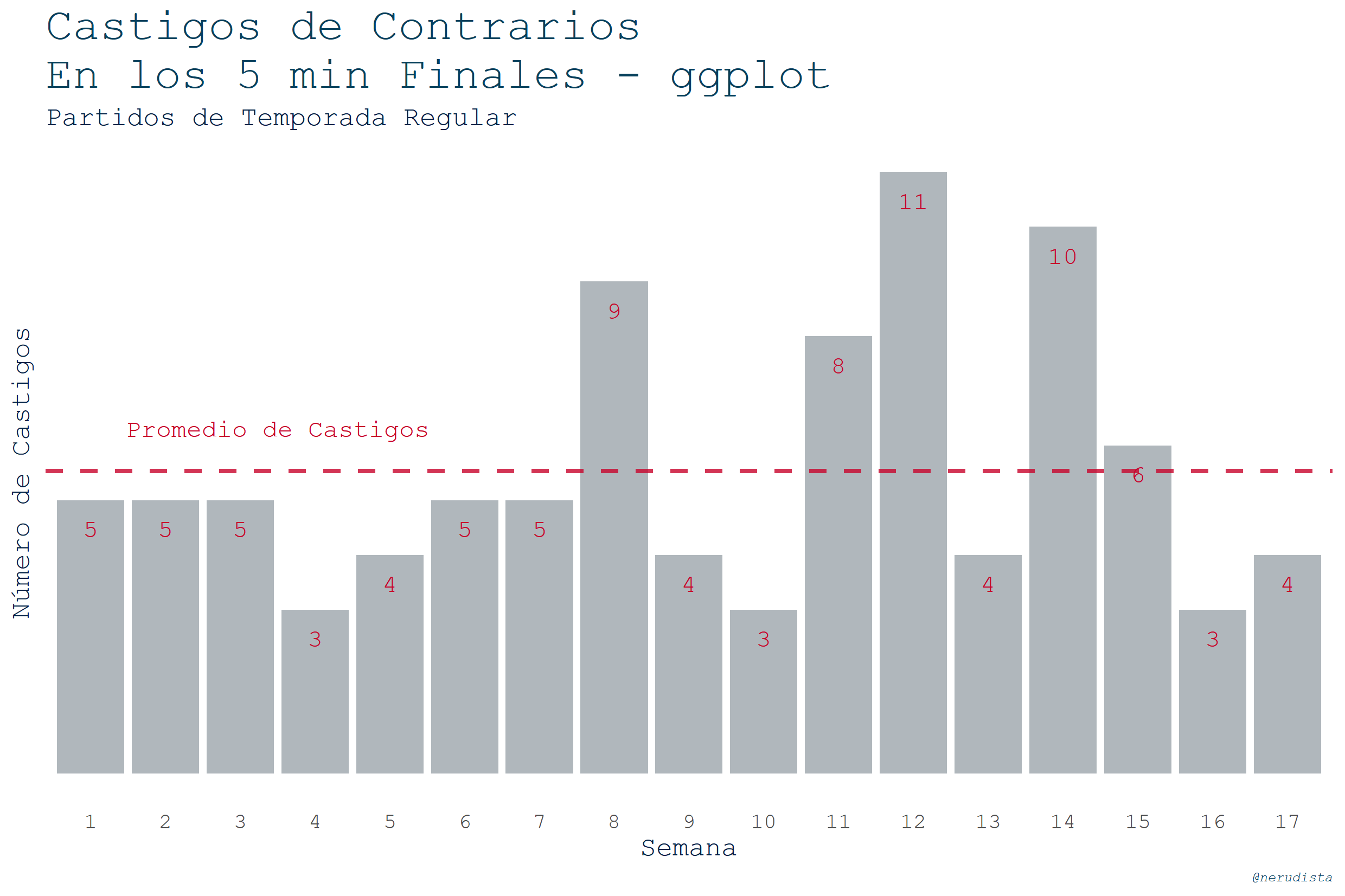
Castigos en los últimos 5 min del último cuarto, de temporada regular, con bar plot y mean lines
Si dicen que a los Pats lo ayudan en los minutos cruciales, pensé que sería bueno analizar los castigos que le marcan a los rivales en los últimos 5 minutos del último cuarto. Para esto, decidí analizar las semanas de la temporada regular y las de postemporada.
Las gráficas de semana regular quedaron de la siguiente manera:
R:
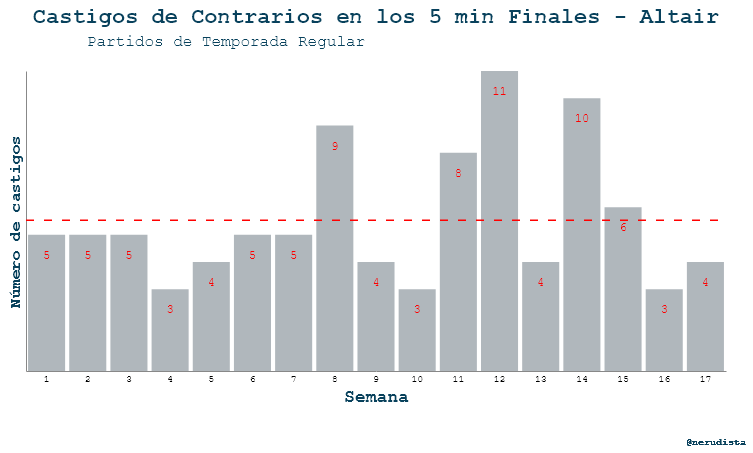
Python:
Y así es como armé el dataset en ambos casos:
R:
library(data.table)
#Create column for minute:second in time left
data$mytime <- strptime(data$time_left_qtr,"%M:%S") %>% as.ITime()
limit <- strptime("05:00","%M:%S") %>% as.ITime()
########## CASTIGOS TEMPORADA REGULAR
df_4q_5min_reg<- data %>%
filter( difftime(data$mytime, limit) < 0 , quarter == "Q4",
game_type=='REG',team_penalty_cat !='NE') %>%
group_by(week) %>%
summarise(count=n())
Python:
from datetime import datetime
#Create column for minute:second in time left
#Esta función pone los minutos como horas y los segundos como minutos.
#Voy a quedarme sólo con los minutos para ver si son los 5 finales
data["mytime"]=pd.to_datetime(data["time_left_qtr"]).dt.hour
data["mytime"]
df_4q_5min_reg =data[(data.mytime-5 < 0) &
(data.quarter == 'Q4') &
(data.game_type=='REG') &
(data.team_penalty_cat != 'NE')].groupby(["week"])["week"].count().reset_index(name="count")
Voy a detenerme un poco en los datasets ya que el manejo del tiempo fue algo interesante en ese ejercicio.
Para ggplot usé el comando strptime para leer la columna time_left_qtr como formato %M:%S (minutos y segundos). Después apliqué as.ITime() para cambiar el tipo de columna. Acto seguido creé una variable limitusando los comandos anteriores para poder usarla en la condición del dataframe: difftime(data$mytime, limit) < 0. Lo que la condición valida es que el tiempo en el reloj menos 5 minutos sea menor que cero. Si fuera mayor, no estaría dentro de los últimos 5 minutos. Esto de jugar con las horas me tomó alrededor de una hora para que funcionara bien.
Para Altair la cosa se puso más interesante. Intenté hacer el mismo acercamiento pero no logré hacerlo porque el to_datetime me mandaba el día en que ejecutaba el comando (por ejemplo, 20 de enero) concatenado al tiempo del reloj. Busqué un rato documentación y ejemplos pero no encontré algo que me funcionara. Así que decidí engañarme un poco.
Usé el comando data["mytime"]=pd.to_datetime(data["time_left_qtr"]).dt.hour para sólo obtener una nueva columna con los minutos del reloj y descartar los segundos. El comando toma los minutos como horas pero como sólo haré una resta pensé que sería útil de todas formas. Este fue el engaño. Al final, el comando para filtrar quedó (data.mytime-5 < 0).
Respecto a las gráficas se habrán dado cuenta que otra vez eran barras y ahora no eran ni stack ni dodge. Así que ¿cuál es la diferencia en esta visualización? Pues que agregué una capa (layer) para la línea que trae el promedio general de castigos.
En ggplot el código es:
plot_4q_5min_reg <- ggplot(df_4q_5min_reg,aes(x=reorder(week, sort(as.numeric(week))) , y=count)) +
geom_bar(stat = "identity",
fill = "#B0B7BC")+ #gray
geom_hline(aes(yintercept = mean(count)),
color='#C8032B',
linetype="dashed",
size=1,
alpha=0.8)+
annotate(geom="text", y=6.3,x=3.5,
label="Promedio de Castigos",
family="mono",
color="#C8032B")+
geom_text(aes(label=count),
family="mono",
vjust=2.5,
color="#C8032B")+
theme(
axis.text.y = element_blank()
)+
xlab("Semana")+
ylab("Número de Castigos")+
labs(title="Castigos de Contrarios\nEn los 5 min Finales - ggplot",
subtitle="Partidos de Temporada Regular",
caption="@nerudista") +
theme_pats_white; plot_4q_5min_reg
La secuencia de pasos de ggplot fue:
- Definir los aes() de la gráfica y hacer un
reorderpara que se ordenen las semanas numéricamente. Sin esto el orden quedaba como 1,11,12,…,2,3,4,etc. - Crear la gráfica de barras con
geom_bar(), - Crear la línea de promedios con
geom_hline. El promedio se especifica conyintercept = mean(count). - Definir una etiqueta para la línea de promedios con
annotate. - Crear la capa para los textos de las barras con
geom_text(). - Generar el titulo y el _caption_inicio.
- Aplicar el theme que ya tenemos definido.
En Altair el código fue:
#plot_4q_5min_reg
bar_5min_reg =alt.Chart(df_4q_5min_reg).mark_bar(color="#B0B7BC").encode(
x=alt.X("week:N",
title="Semana",
axis=alt.Axis(ticks=False, labelAngle = 0), #pone los número de semana sin voltear
),
y=alt.Y("count:Q", title="Número de castigos")
).properties(
width = 700,
height=300
)
text_5min_reg = alt.Chart(df_4q_5min_reg).mark_text(
dy=20,
font="Courier",
fontSize=12,
color='red').encode(
x=alt.X('week:N'),
y=alt.Y('count:Q',axis=None),
text=alt.Text('count:Q')
)
rule = alt.Chart(df_4q_5min_reg).mark_rule(strokeDash=[8,10],color='red').encode(
y= alt.Y('mean(count):Q'),
size=alt.value(1.5),
)
base_5min_reg = alt.layer(bar_5min_reg , text_5min_reg , rule).properties(
width = 700,
height=400
)
base_5min_reg
title = alt.Chart(
{"values": [{"text": "Castigos de Contarios en los 5 Minutos Finales"}]}
).mark_text(size=20, color="#08415C", font='Courier').encode(
text="text:N"
).properties(
width = 400,
height=5
)
subtitle = alt.Chart(
{"values": [{"text": "Partidos de Temporada Regular"}]}
).mark_text(size=16, color="#08415C", font='Courier').encode(
text="text:N"
).properties(
width = 400,
height=10
)
final_5min_reg= alt.vconcat(#title,
subtitle,
base_5min_reg,
caption_chart).properties(
title="Castigos de Contrarios en los 5 min Finales - Altair" )
final_5min_reg
Si bien el código se ve más largo por el tema de la concatenación vertical de gráficas, el inicio es muy parecido:
- Crear chart.
- Crear la gráfica de barra con
mark_bar(). - Crear otra gráfica para los textos arriba de las barras con
mark_text(). - Crear la capa con el promedio de castigos con
mark_rule(). - Hacer una layer chart para unir las tres capas anteriores anteriores.
- Crear subtítulo.
- Crear una gráfica para el caption (esta ya la traemos desde el inicio pero la pongo para que quede en los pasos.)
- Concatenar verticalmente la layer chart con el caption y el subtitle
- Ajustar el título
De nueva cuenta en Altair no logré quitar el eje Y por completo. Pude quitar los labels y los ticks pero no la línea del eje. Como aquí no hay ningún legend no se ve el problema de la separación entre el título , el subtítulo y la gráfica. Si no sabes de qué hablo, más abajo tengo más ejemplos.
Ahora vayamos con las semanas de postemporada.
Castigos en los últimos 5 min del último cuarto, de postemporada, con stack bar plots
Misma premisa: qué tanto ayudan a los Pats, al castigar a los contrarios, en los últimos minutos del partido pero ahora en partidos de eliminación.
Van las gráficas:
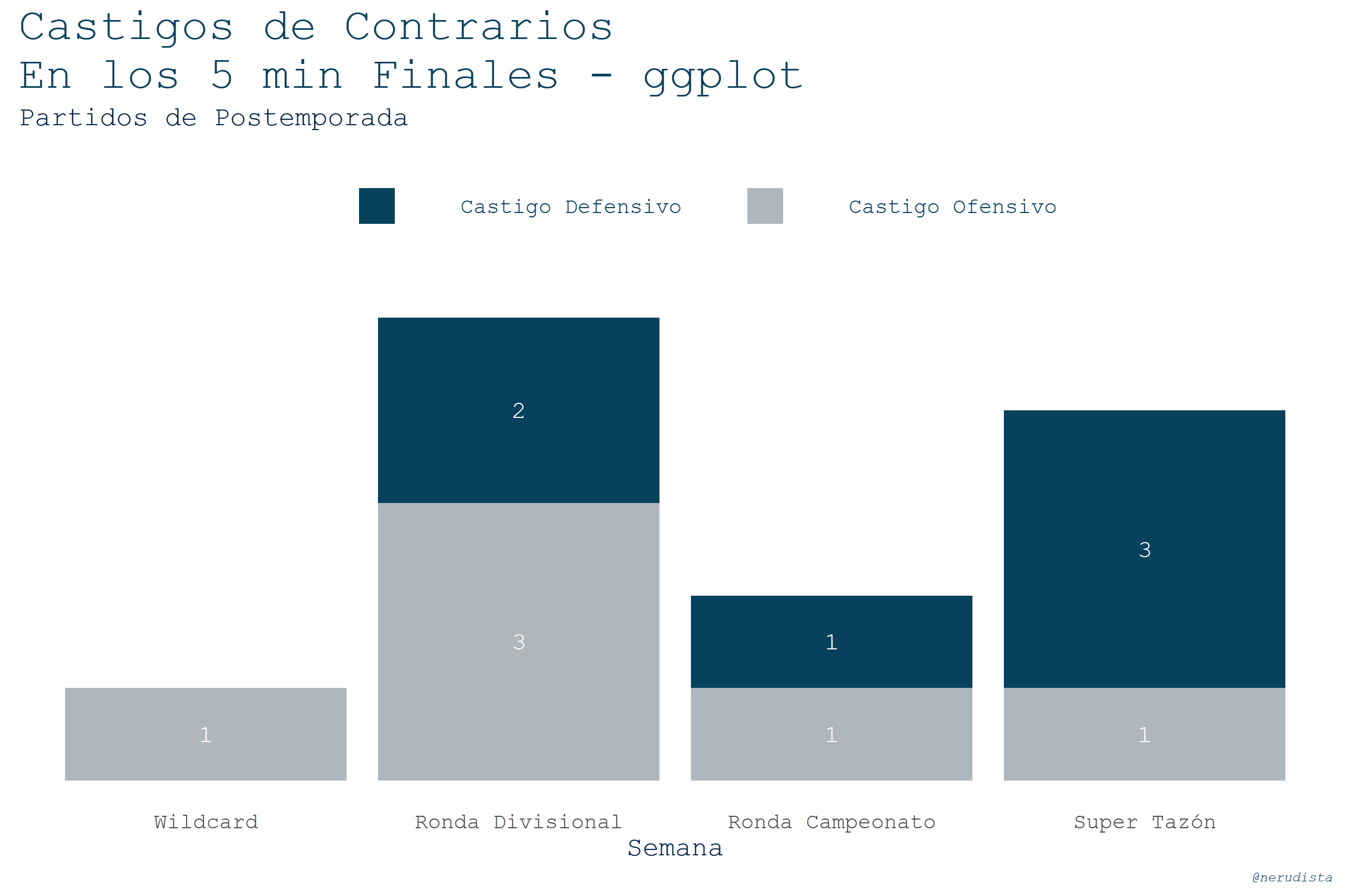
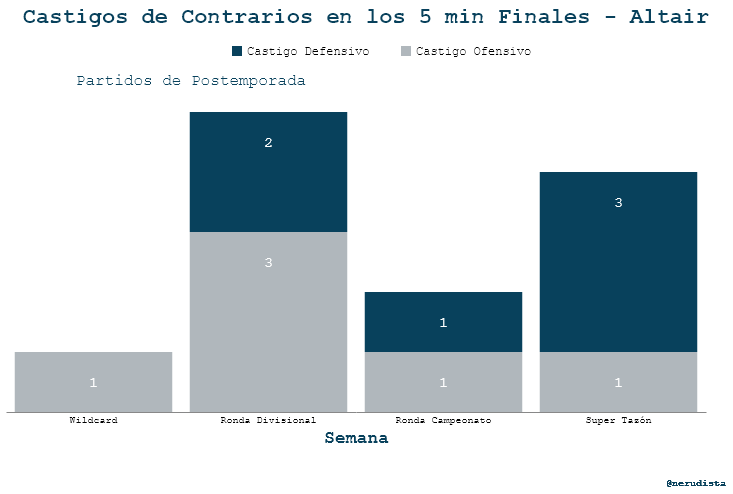
Estos son los códigos para la creación de los dataframes:
R:
########## CASTIGOS POST-TEMPORADA
#El dataset tiene un error. EL SB de 2014 lo pone como Week 5 y debe ser 4
data$week <- ifelse( data$game_type=='POST' & data$week==5,
'4',
data$week)
df_4q_5min_post<- data %>%
filter( difftime(data$mytime, limit) < 0 , quarter == "Q4",
game_type=='POST',team_penalty_cat !='NE') %>%
group_by(week_type,penalty_side) %>%
summarise(count=n())
#Cambiar los labels, de los levels, de team_penalty_cat
df_4q_5min_post$week_type <- factor(df_4q_5min_post$week_type,
levels = c("Wildcard", "Ronda Divisional",
"Ronda Campeonato","Super Tazón")
)
Para ggplot arreglé un error que tiene el dataset: había un partido que estaba como semana 5 cuando debía ser 4. Eso lo arreglé con el ifelse. Además cambié los levels de la columna week_type para cambiar de semana 1,2,3,4 a Wildcard, Ronda Divisional, etc.
Ahora el dataset de Python:
########## CASTIGOS POST-TEMPORADA
def corregir_semana_sb(df):
if df.game_type == 'POST':
if df.week == 1:
return "Wildcard"
elif df.week == 2:
return "Ronda Divisional"
elif df.week == 3:
return "Ronda Campeonato"
else:
return "Super Tazón"
data["myweek"]=data.apply(corregir_semana_sb,axis=1)
df_4q_5min_post =data[(data.mytime-5 < 0) &
(data.quarter == 'Q4') &
(data.game_type=='POST') &
(data.team_penalty_cat != 'NE')].groupby(["myweek","penalty_side"])["myweek"].count().reset_index(name="count_pen")
df_4q_5min_post
Acá hice una función llamada corregir_semana_sb que después apliqué con un apply en Pandas. Aquí de plano cambié el valor de los datos y no solo el “level” como en R. Intenté buscar algo similar en Python pero no lo encontré. Por eso me decidí a cambiar directamente el valor aunque no me encanta.
Ahora va el código de ggplot para la gráfica:
plot_4q_5min_post <- ggplot(df_4q_5min_post,
aes(x=week_type,
y=count ,
fill=penalty_side)) +
geom_bar(stat = "identity",
position = "stack")+
geom_text( aes(label=count),
family="mono",
position=position_stack(vjust = .5),
vjust=0.5,
color="#FFFFFF"
)+
xlab("Semana")+
labs(title="Castigos de Contrarios\nEn los 5 min Finales - ggplot",
subtitle="Partidos de Postemporada",
caption="@nerudista") +
guides(fill=guide_legend(title=NULL))+ #remove legend title
scale_fill_manual(values=c("#08415C", "#B0B7BC"))+
theme(
axis.text.y = element_blank(),
axis.title.y = element_blank()
)+
theme_pats_white; plot_4q_5min_post
La secuencia de pasos fue:
- Definir los
aes()de la gráfica incluyendo elfillpara establecer el color de la barra apilada. - Crear la gráfica de barra.
- Sobre la anterior crear la gráfica para los textos arriba de las barras.
- Crear el título, subtítulo y el caption.
- Aplicar el tema de los Pats que estamos usando.
Para Altair el código es:
bar_5min_post = alt.Chart(df_4q_5min_post).mark_bar().encode(
x =alt.X("myweek:N",
sort=['Wildcard', 'Ronda Divisional', 'Ronda Campeonato','Super Tazón'],
title="Semana",
axis=alt.Axis(labelAngle=0 , ticks=False),
),
y=alt.Y("count_pen:Q", stack='zero', axis=None),
color=alt.Color('penalty_side',
legend=alt.Legend(direction="horizontal",
orient="none",
legendX=250,
legendY=0,
columnPadding=30,
padding=-25,)
)
).properties(
width= 700,
height=300)
text_5min_post = alt.Chart(df_4q_5min_post).mark_text(
font="Courier",
fontSize=15,
dy=30,
color='white'
).encode(
x =alt.X("myweek:N",
sort=['Wildcard', 'Ronda Divisional', 'Ronda Campeonato','Super Tazón'],
axis=None),
y=alt.Y("count_pen:Q", stack='zero',axis=None),
detail='penalty_side:N',
text=alt.Text('count_pen:Q' )
).properties(
width= 700,
height=300)
base_5min_post= alt.layer( bar_5min_post,text_5min_post )
base_5min_post
subtitle = alt.Chart(
{"values": [{"text": "Partidos de Postemporada"}]}
).mark_text(dx=-165 ,size=16, color="#08415C", font='Courier').encode(
text="text:N"
).properties(
width = 700,
height=0
)
subtitle
final_5min_post= alt.vconcat(
subtitle,
base_5min_post,
caption_chart).properties(
title="Castigos de Contrarios en los 5 min Finales - Altair" )
La lógica de esta gráfica es fue:
- Crear un chart con un
mark_bar(). Elcolores el que nos va ayudar con la barra apilada. - Crear un chart con un
mark_text(). En este paso y el anterior puse explícitamente el sort del tipo de semana. - Hacer una layer chart para unir las dos anteriores.
- Crear una gráfica para el caption.
- Crear una gráfica para el subtitle.
- Concatenar verticalmente la layer chart con el caption y el subtitle.
- Poner el título de la gráfica.
Aquí podemos ver el error que mencionaba en la gráfica anterior. El legend queda justo debajo del título y no debajo del subtítulo. Si son observadores, podrán darse cuenta que la línea del eje X tampoco desapareció por completo.
Esta gráfica es muy similar a una del post pasado sólo que aquí le metí lo del sort. Seguro les puede servir más adelante.
Castigos en juegos de una posesión o cómo diablos uso el facet para duplicar gráficas
Aquí intenté ver qué tanto ayudan a los Pats en juegos que se decidieron por menos de 8 puntos. Es decir, una posesión de balón.
Va el resultado de los dos lenguajes:
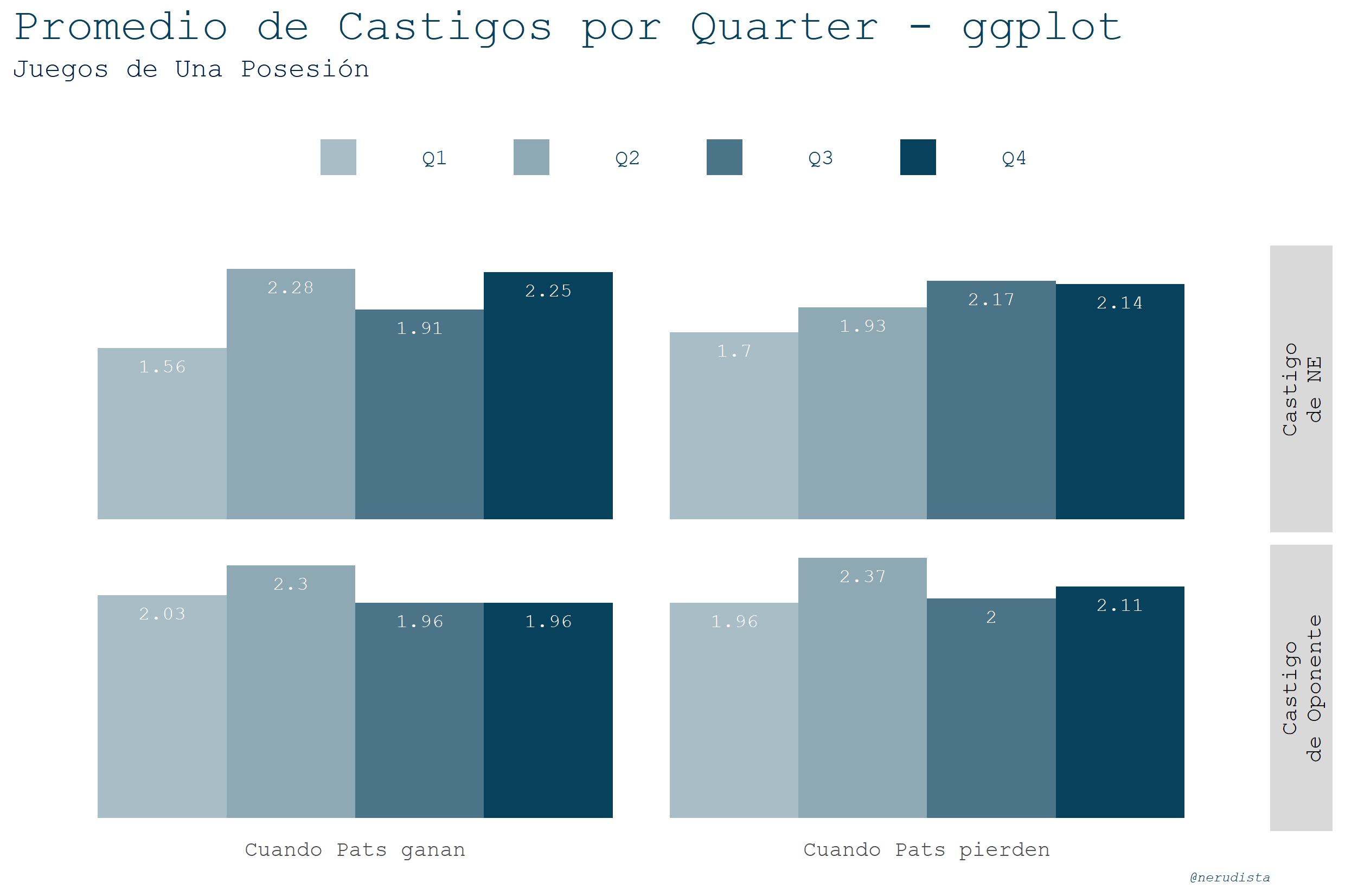
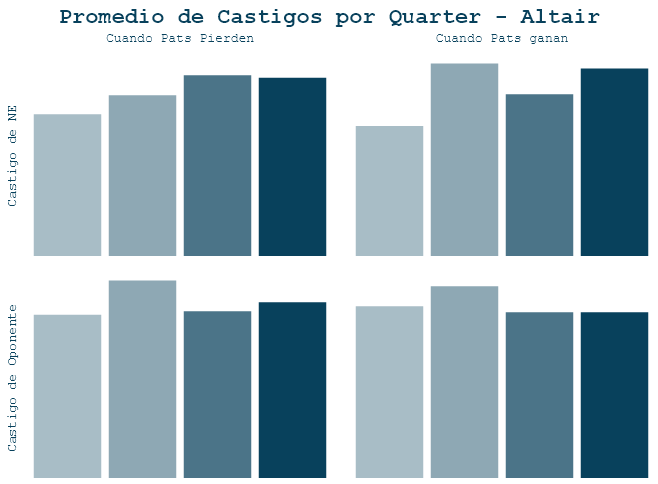
Los dataframes para esta viz fueron:
R
df_juegos_posesion <- data %>%
group_by(game_winner_cat,team_penalty_cat,season,week,quarter,one_posession_game) %>%
filter(one_posession_game=='Juego de una posesión', quarter != 'Q5') %>%
summarise(cnt_pen=n())%>%
group_by(game_winner_cat,team_penalty_cat,quarter,one_posession_game)%>%
summarise(mean_pen=round(mean(cnt_pen),2))
#Cambiar los labels, de los levels, de team_penalty_cat
df_juegos_posesion$team_penalty_cat <- factor(df_juegos_posesion$team_penalty_cat,
levels = c("NE", "Oponente"),
labels = c("Castigo\nde NE", "Castigo\nde Oponente"))
En este dataframe anidé dos group_by con su respectivo summarise y además tiene un filter. De nueva cuenta cambié los levels de un campo para que las etiquetas de la gráfica tuvieran la cadena que yo quería.
En Python el código fue:
pre_df_juegos_posesion = data.groupby(["game_winner_cat","team_penalty_cat","season","week","quarter",\
"one_posession_game"])["game_winner_cat"].count().reset_index(name="cnt_pen")
pre_df_juegos_posesion[:6]
df_juegos_posesion= pre_df_juegos_posesion.groupby(["game_winner_cat","team_penalty_cat","quarter",\
"one_posession_game"])["cnt_pen"].mean().round(2).reset_index(name="mean_pen")
df_juegos_posesion.game_winner_cat=\
df_juegos_posesion.game_winner_cat.apply(lambda x : 'Cuando Pats ganan' if x=="NE" else 'Cuando Pats Pierden' )
df_juegos_posesion.team_penalty_cat=\
df_juegos_posesion.team_penalty_cat.apply(lambda x : 'Castigo de NE' if x=="NE" else 'Castigo de Oponente' )
df_juegos_posesion[:3]
En este caso hice el dataframe en dos pasos pero aquí no use un filter. Ese lo pondré con Altair para que puedan examinar después el JSON que genera. Al igual que en gráficas pasadas, cambié directamente el valor de los datos pero esta vez con funciones lambda. Para ser honesto, me parecen una chulada de maíz prieto.
Pasemos al código de ggplot:
plot_juegos_1_posesion <- ggplot(df_juegos_posesion,
aes(x=game_winner_cat, y=mean_pen, fill=quarter))+
geom_bar( stat = "identity",
position = "dodge")+
geom_text( aes(label=mean_pen),
family="mono",
position=position_dodge(width=.9),
vjust=2,
size=3,
color="#FFFFFF"
)+
facet_grid( team_penalty_cat ~ . ) +
scale_x_discrete(labels=c("Cuando Pats ganan","Cuando Pats pierden"))+
scale_fill_manual(values=c("#a8bdc6","#8ea8b4","#4b7488","#08415C"))+
labs(title="Promedio de Castigos por Quarter - ggplot",
subtitle="Juegos de Una Posesión",
caption="@nerudista") +
guides(fill=guide_legend(title=NULL))+ #remove legend title
scale_y_continuous(breaks=NULL)+ #remove y axis numbers
theme_pats_white+
theme(
#titulos del facet
strip.text.y = element_text(size = 10, colour = "black", angle = 90),
#remover titulos de los ejes
axis.title.y = element_blank(),
axis.title.x = element_blank()
); plot_juegos_1_posesion;
Si se fijan atentamente, la gráfica original es una barra dodge que se va a replicar. Esta replicación la vamos a hacer con facet_grid( team_penalty_cat ~ . ) . team_penalty_cat es el campo que hace la diferencia entre dodge bars.
Va la secuencia de pasos:
- Definir los aes() de la gráfica. Recuerden el
fillpara la escala de color que usaremos después. - Crear la gráfica de barras con
geom_bar()y usando elposition = "dodge". - Crear la capa de texto con
geom_text. Para que los textos se acomoden tuve que usarposition=position_dodge(). - Replicar las gráficas con
facet_grid( team_penalty_cat ~ . ) - Cambiar los los labels del eje X.
- Definir la paleta de colores que usaré para las barras con
scale_fill_manual(). - Crear el título, subtítulo y el caption.
- Aplicar el theme que ya tenemos definido.
Para Altair la cosa se puso color de hormiga. Si revisan bien la gráfica pueden darse cuenta que no tiene un layer para el texto. Vamos por pasos. Primero hice la capa de las barras:
domain = ['Q1', 'Q2', 'Q3','Q4']
range_ = ["#a8bdc6","#8ea8b4","#4b7488","#08415C"]
bar_juegos_1_posesion = alt.Chart(df_juegos_posesion[(df_juegos_posesion.one_posession_game=='Juego de una posesión' ) & \
(df_juegos_posesion.quarter !='Q5' )]).mark_bar(
).encode(
x = alt.X(alt.repeat("column"),
type='ordinal',
axis=None),
y = alt.Y(alt.repeat("row"), type='quantitative', axis=None),
column="game_winner_cat",
row="team_penalty_cat",
color=alt.Color('quarter', scale=alt.Scale(domain=domain, range=range_),
legend=None),
).properties(
width = 300
).repeat(
row=['mean_pen'],
column=['quarter'],
title="Promedio de Castigos por Quarter - Altair"
).configure_header(
title=None,
labelFont="Courier",
labelFontSize=13,
labelAlign="center",
labelColor="#08415C",
)
bar_juegos_1_posesion
Van los pasos para esta capa:
- Crear dos listas: una para el rango y otra para el dominio de los datos. En el dominio puse los distintos valores del campo
quartery en el rango puse la paleta de colores que voy a usar para cada valor. - Crear chart poniendo el filtro dentro del
chart(). - Crear la gráfica de barra con
mark_bar(). - En el
encodedefiní elalt.repeat("column"),en el eje X yalt.repeat("row")en el eje Y. Si se fijan, ahí no puse qué campo voy a usar solo que voy a repetir. - Usar la paleta de color dentro de
alt.Scale()que está dentro dealt.Color() - Cambiar el ancho de cada gráfica para que quepa en pantalla. Eso es con
width = 300dentro deproperties. - Usar
repeatpara especificar qué campos se van a usar para los row y el column que pusimos en elencodedel paso 4.
Después generé la capa de los textos:

Con este código:
text_juegos_1_posesion = alt.Chart(df_juegos_posesion[(df_juegos_posesion.one_posession_game=='Juego de una posesión' ) & \
(df_juegos_posesion.quarter !='Q5' )]).mark_text(
font="Courier",
fontSize =12,
).encode(
x = alt.X(alt.repeat("column"),
type='ordinal',
axis=None),
y = alt.Y(alt.repeat("row"), type='quantitative', axis=None),
column="game_winner_cat",
row="team_penalty_cat",
text= alt.Text("mean_pen:Q")
).properties(
width = 300
).repeat(
row=['mean_pen'],
column=['quarter'],
)
text_juegos_1_posesion.save('./graficas/Altair/AltairJuegosUnaPosesionText.png', scale_factor=1.0)
text_juegos_1_posesion
Sin embargo, cuando quise unir las capas con bar_juegos_1_posesion + text_juegos_1_posesion apareció este error:
ValueError: Objects with "config" attribute cannot be used within LayerChart. Consider defining the config attribute in the LayerChart object instead
Intenté de varias formas unirlas pero no lo logré. Es la espina que más se me queda clavada de todo el ejercicio. Si alguien me puede pasar tips para terminarla, se los agradeceré muchísimo.
Correlación entre puntos recibidos y yardas con scatterplots
Hora de cambiar de tipo de gráfica. Quise ver si había algún tipo de correlación entre los puntos que les anotan a los Pats y los castigos que les son marcados a sus oponentes.
Va el resultado de ambas #BibliotecasNoLibrerias
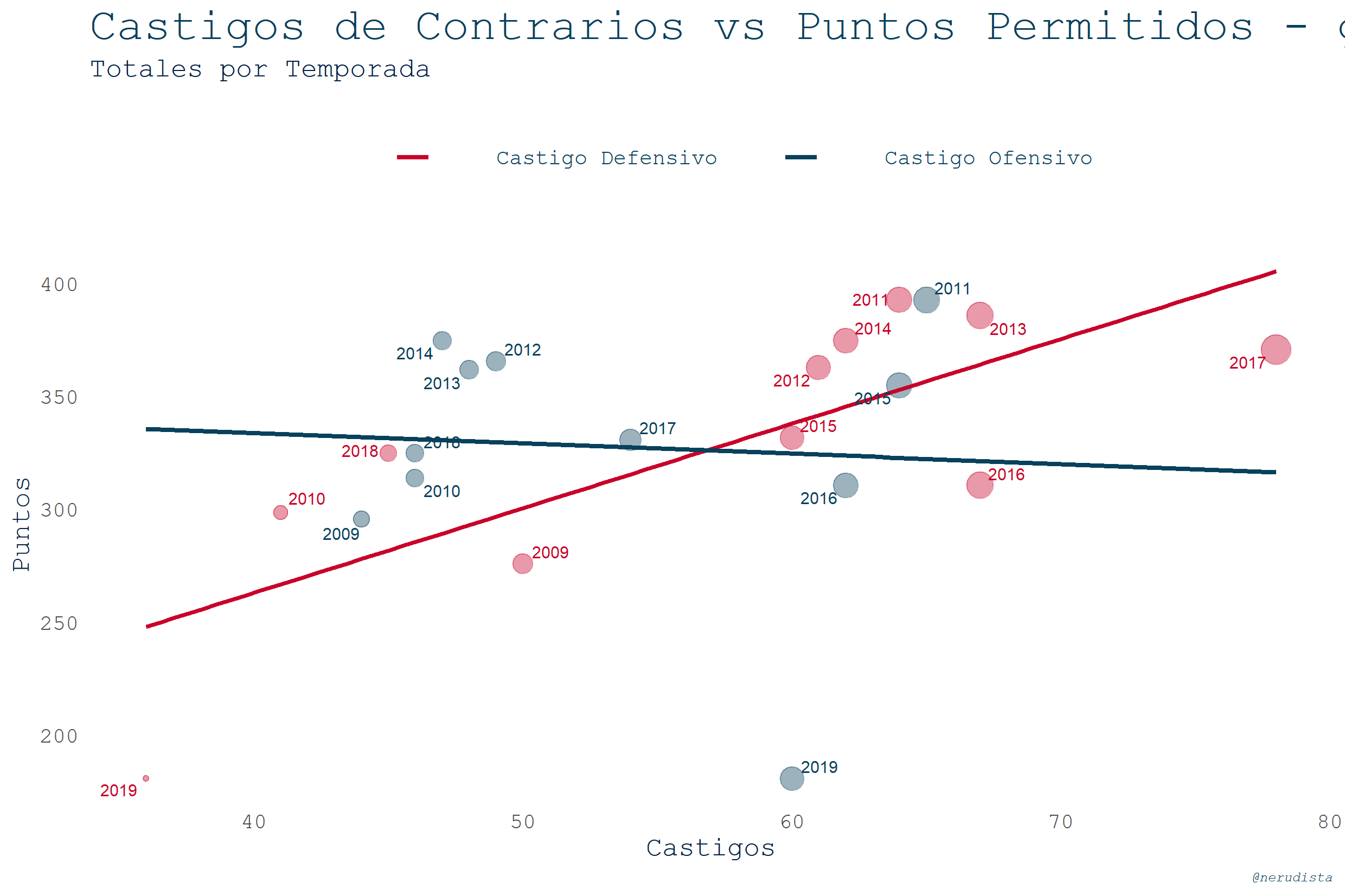
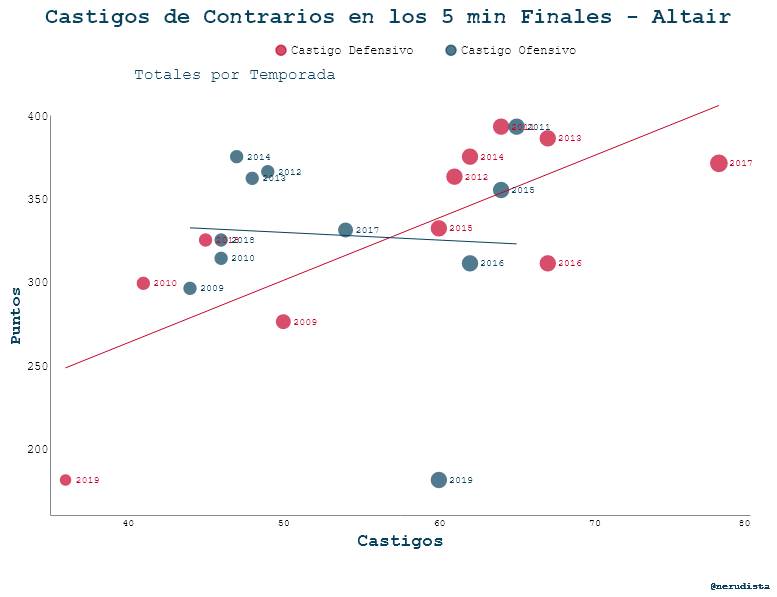
Y ahora toca ver los dataframes:
R:
df_temporada_help <- data %>%
group_by(season,week,team_penalty_cat,penalty_side,game_type) %>%
summarise(cnt_pen_game=n(),
pats_points_game=mean(pats_points),
opp_points_game=mean(opps_points)) %>%
filter ( team_penalty_cat == 'Oponente') %>%
group_by(season,penalty_side) %>%
summarise(sum_pen_season=sum(cnt_pen_game),
opp_points_season=sum(opp_points_game))
De nueva cuenta anidé dos group_by - summarise y un filter para tener los datos ya limpios y pasarlos a ggplot.
Python
df_temporada_help = data.groupby(["season","week","team_penalty_cat","penalty_side","game_type"]).agg(\
pats_points_game = ('pats_points','mean'),
opp_points_game = ('opps_points','mean'),
cnt_pen_game = ('opps_points','count'),
).reset_index().groupby(["season","penalty_side","team_penalty_cat"]).agg(\
sum_pen_season = ('cnt_pen_game','sum'),
opp_points_season= ('opp_points_game','sum')
).reset_index()
df_temporada_help[:3]
Esta vez en Python repliqué el concatenamiento de groupby pero ahora usé la función agg() para traer diferentes métricas de cada agrupación. La diferencia con R es que aquí no filtré team_penalty_cat == 'Oponente'. Eso lo haré ya en Altair con un transform_filter().
Este fue el código de la gráfica en R:
#biblioteca para textos en scatter
library(ggrepel)
plot_temporada_help <- ggplot( df_temporada_help,aes(x=sum_pen_season, y=opp_points_season))+
geom_point(aes(color=penalty_side,
#shape=penalty_side,
size = sum_pen_season,
),
show.legend = FALSE, #esto elimina el legend de los bubbles
alpha = 0.4) +
geom_smooth(aes(color=penalty_side, #crea linea de regresion
fill = penalty_side
),
se=FALSE,
alpha=0.2,
method = lm,
fullrange = TRUE)+
geom_text_repel(aes(label = season, color = penalty_side),
size = 2.5,
show.legend = FALSE
)+ #label de dots
scale_color_manual(values = c("#C8032B", "#08415C"))+
xlab("Castigos")+
ylab("Puntos")+
labs(caption="@nerudista",
title="Castigos de Contrarios vs Puntos Permitidos - ggplot",
subtitle="Totales por Temporada"
)+
theme(
#axis.line = element_line(),
legend.title = element_blank(),
legend.key = element_rect(fill="#FFFFFF"), #quita el color gris de la línea de castigos
legend.position = c(0.7, 0.35)
) + theme_pats_white; plot_temporada_help;
La secuencia fue:
- Importar la biblioteca
ggrepelpara evitar que los textos dentro del scatter se traslapen. - Definir los
aes()de la gráfica. - Crear la capa de puntos con
geom_point(). Usé los parámetroscolorysizepara asignar colores al tipo de castigo y tamaño al número de castigos marcados. - Generar la línea de regresión para ambos tipos de castigos con
geom_smooth(). Para no complicar el asunto. Usé una regresión líneal conmethod = lm. - Contruir la capa de textos con
geom_text_repel(). - Poner el título, subtítulo y caption.
- Aplicar el theme de los Pats.
Ahora vámonos con Altair:
range_=["#C8032B","#08415C"]
domain=["Castigo Defensivo","Castigo Ofensivo"]
scatter_temporada_help_2 =alt.Chart(df_temporada_help).transform_filter(
"datum.team_penalty_cat == 'Oponente'"
).mark_circle().encode(
x=alt.X("sum_pen_season:Q",
scale=alt.Scale(zero=False,
bins = [30,40,50,60,70,80],) ,
axis = alt.Axis(labels=True, ticks=False)
),
y=alt.Y("opp_points_season:Q",title="Puntos",
scale=alt.Scale(zero=False,
domain=(160,400), #para que no empiece desde cero el eye Y
bins = [100,150,200,250,300,350,400]),
axis = alt.Axis(labels=True, ticks=False),
),
color= alt.Color("penalty_side",
scale=alt.Scale(domain=domain, range=range_),
legend=alt.Legend(direction="horizontal",
orient="none",
legendX=250,
legendY=0,
columnPadding=30,
padding=-25,
)
),
size= alt.Size('sum_pen_season', legend=None,bin=True),
).properties(
width = 700,
height= 400
)
scatter_reg_temorada_help = scatter_temporada_help_2 + scatter_temporada_help_2.transform_regression(
on='sum_pen_season',regression ='opp_points_season', method="linear" , groupby=['penalty_side']
).mark_line(size = 4)
text_temporada_help = alt.Chart(df_temporada_help[df_temporada_help.team_penalty_cat == 'Oponente']).mark_text(
align='left',
baseline='middle',
dx=10,
size=10,
#color="red",
font="Courier"
).encode(
x=alt.X("sum_pen_season:Q", title="Castigos"),
y=alt.Y("opp_points_season:Q",title="Puntos"),
text='season',
color= alt.Color("penalty_side:N",
#scale=alt.Scale(domain=domain, range=range_),
),
)
base_temporada_help =alt.layer(scatter_reg_temorada_help , text_temporada_help)
subtitle = alt.Chart(
{"values": [{"text": "Totales por Temporada"}]}
).mark_text(dx=-165 ,size=16, color="#08415C", font='Courier').encode(
text="text:N"
).properties(
width = 700,
height=10
)
final_temporada_help= alt.vconcat(
#subtitle,
base_temporada_help,
caption_chart).properties(
title="Castigos de Contrarios en los 5 min Finales - Altair" )
Estos son los pasos a seguir:
- Crear dos listas: una para el rango y otra para el dominio de los datos. En el dominio puse los distintos valores del campo
penalty_sidey en el rango puse la paleta de colores que voy a usar para cada valor. - Usar un
transform_filter()para agarrar sólo los castigos hechos por oponentes"datum.team_penalty_cat == 'Oponente'". Si se fijan, el JSON que se va a generar para la gráfica sí va a traer todos los datos aunque no los usemos. Es por esto que en los anteriores ejemplos filtré desde antes pero para este ejercicio lo hice diferente para que puedan comparar el JSON que se genera. - Crear la gráfica de puntos con
mark_circle(). Aquí puse especial enfasis en poner las escalas del eje X y Y con los mismos saltos que en ggplot, por ejemplobins = [100,150,200,250,300,350,400]en el eje Y - Usar la gráfica de puntos para agregarle un
transform_regressionque cree las líneas de regresión líneal porpenalty_side. - Generar no una capa sino otro
chartpara los textos. Aquí sí filtre desde el dataframe que le estoy pasando a Altair. - Hacer una layer chart para unir los dos
chartanteriores. - Crear subtítulo.
- Crear una gráfica para el caption (esta ya la traemos desde el inicio pero la pongo para que quede en los pasos.)
- Concatenar verticalmente la layer chart con el caption y el subtitle.
- Ajustar el título.
Para Altair me quedan los problemas ya muy comentados: no pude quitar las líneas de los ejes y la leyenda queda entre el título y el subtítulo.
Este ejercicio sí me tomó bastantes horas sobre todo para entender los diferentes transform_*() que se pueden usar.
La última y nos vamos: castigos por temporada con line plots
De las gráficas básicas me faltaba hacer un line plot asi que pensé que graficar el número de castigos por temporada sería una buena idea.
Así quedó el ejercicio en ggplot:
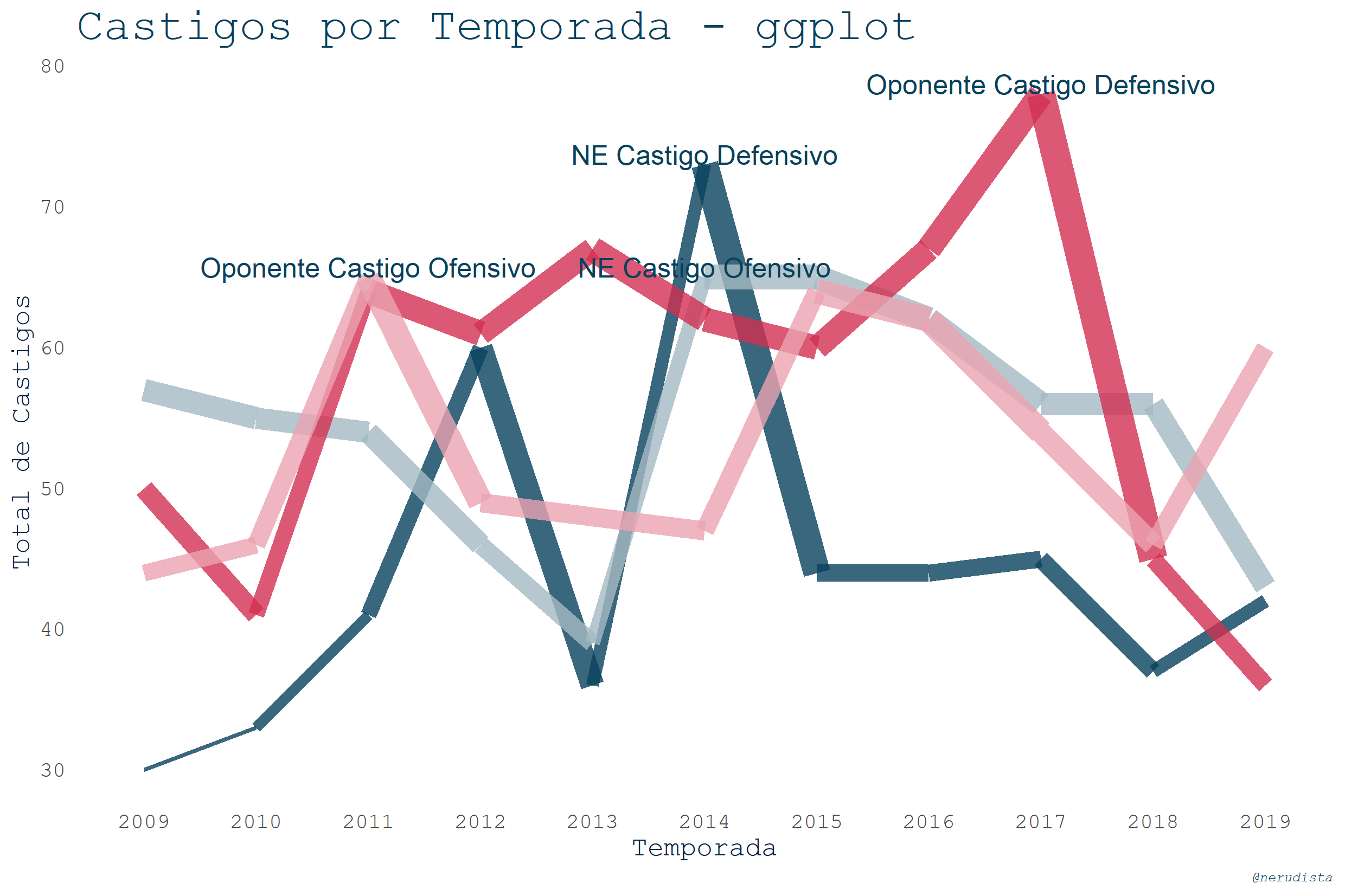
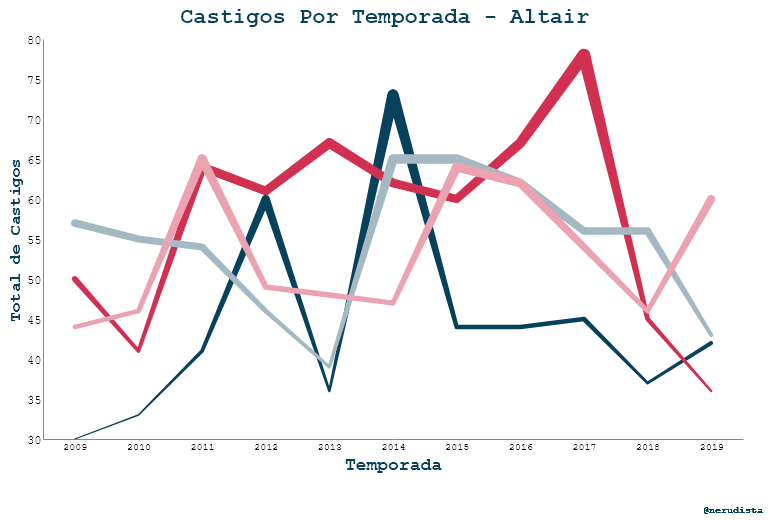
Y así el de Altair:
Veamos como se hicieron los dataframes:
## R dataframe ##
df_temporada_help_all <- data %>%
group_by(season,week,team_penalty_cat,penalty_side,game_type) %>%
summarise(cnt_pen_game=n(),
pats_points_game=mean(pats_points),
opp_points_game=mean(opps_points)) %>%
group_by(season,team_penalty_cat,penalty_side) %>%
summarise(sum_pen_season=sum(cnt_pen_game),
opp_points_season=sum(opp_points_game))
#Crear columna para unir el tipo de castigo y quién lo hizo
df_temporada_help_all$cat_made <- paste(df_temporada_help_all$team_penalty_cat,df_temporada_help_all$penalty_side)
## Pandas dataframe ##
df_temporada_help = data.groupby(["season","week","team_penalty_cat","penalty_side","game_type"]).agg(\
pats_points_game = ('pats_points','mean'),
opp_points_game = ('opps_points','mean'),
cnt_pen_game = ('opps_points','count'),
).reset_index().groupby(["season","penalty_side","team_penalty_cat"]).agg(\
sum_pen_season = ('cnt_pen_game','sum'),
opp_points_season= ('opp_points_game','sum')
).reset_index()
#Crear columna para unir el tipo de castigo y quién lo hizo
df_temporada_help["cat_made"]=df_temporada_help["team_penalty_cat"]+' '+df_temporada_help["penalty_side"]
df_temporada_help[:3]
En ambos casos concatené las agrupaciones y al final hice una nueva columna (cat_made) en el dataframe para concatenar el tipo de castigo con el equipo castigado.
Ahora veamos el código de ggplot
library(directlabels)
plot_temporada_all <- ggplot(df_temporada_help_all,aes(x=season,
y=sum_pen_season,
group=cat_made)) +
geom_line(aes(color=cat_made, size=sum_pen_season),
show.legend = TRUE,
alpha = .8)+
geom_dl(aes(label = cat_made), #esto es de directlabels
#method = list(dl.trans(x = x + .2), "last.points")
#method = list( "smart.grid",cex=.8)
#method = list( "last.points",rot=30,colour="#08415C",family="mono")
#method="top.points"
method=list("top.bumptwice",colour="#08415C",family="mono")
#method = list(dl.trans(x = x + .2), "first.points")
) +
scale_color_manual(values=c("#08415C","#a5b9c3","#d23051","#eba3b1"))+
xlab("Temporada")+
ylab("Total de Castigos")+
guides(size=FALSE,color=FALSE)+
labs(caption="@nerudista",
title="Castigos por Temporada - ggplot"
#subtitle="Totales por Temporada"
)+
theme(
legend.position = "top",
legend.box = "vertical",
legend.title = element_blank(),
)+
theme_pats_white; plot_temporada_all;
Los pasos para la gráfica fueron:
- Importar la biblioteca
directlabelspara poner textos sobre la line plot. - Definir los
aes()de la gráfica. Aquí el truco está engroup=cat_madepara crear una línea por cada combinación de la nueva columna que creamos. - Crear la capa de líneas con
geom_line(). Usé los parámetroscolorysizepara asignar colores al tipo de castigo y tamaño a la línea. - Generar la capa de textos con
geom_dl(). Hay muchos métodos para colocar las etiquetas. En el código dejé varios para que puedan jugar. - Asignar la escala de colores a usar con
scale_color_manual(). - Poner el título, subtítulo y caption.
- Aplicar el theme de los Pats.
Ahora veamos el código de Altair:
domain=["NE Castigo Defensivo","NE Castigo Ofensivo","Oponente Castigo Defensivo","Oponente Castigo Ofensivo"]
range_=["#08415C","#a5b9c3","#d23051","#eba3b1"]
#line_temporada_all
base_temporada_all = alt.Chart(df_temporada_help).mark_trail().encode( #trail y no line para poder cambiar el ancho de la línea
x = alt.X("season:N",
title="Temporada",
axis = alt.Axis(ticks=False, labels=True, labelAngle=0)),
y = alt.Y("sum_pen_season:Q",
title="Total de Castigos",
axis = alt.Axis(ticks=False, labels=True),
scale = alt.Scale (zero=False,)
),
color = alt.Color("cat_made:N",
scale = alt.Scale(domain=domain, range=range_),
legend= None),
size= alt.Size("sum_pen_season:Q", legend=None,
scale= alt.Scale(domain=[30,100], range=[1,18])
)
).properties(
width = 700,
height = 400
)
base_temporada_all= alt.vconcat(
#subtitle,
base_temporada_all,
caption_chart).properties(
title="Castigos Por Temporada - Altair" )
base_temporada_all
- Crear dos listas: una para el rango y otra para el dominio de los datos. En el dominio puse los distintos valores del nuevo campo
cat_madey en el rango puse la paleta de colores que voy a usar para cada valor. - Crear la gráfica de puntos con
mark_trail(). El truco aquí, para poder asignar tamaño a la línea, es usarmark_trail()y nomark_line(). - Asignar el rango y dominio para los colores dentro del
scale = alt.Scale(domain=domain, range=range_). - Usar
scale= alt.Scale(domain=[30,100], range=[1,18]para jugar con el tamaño de la línea. - Crear una gráfica para el caption (esta ya la traemos desde el inicio pero la pongo para que quede en los pasos.)
- Concatenar verticalmente la layer chart con el caption y el subtitle.
- Ajustar el título.
Para Altair no logré poner textos sobre las gráficas pero sí logré igualar los breaks de los ejes aunque seguí sin poder quitar las líneas de ellos. Para ser honesto, las líneas de este úlitmo ejercicio me gustan mucho más que las de ggplot pero no poder poner etiquetas me sigue dando comezón. De nueva cuenta cualquier ayuda es bienvenida.
(Mis) Conclusiones
Esta aventura que inició con un simple tuit se volvió un proyecto de casi mes y medio, incluyendo el tiempo de creación de estas entradas para el blog de tacos de datos. De las cosas nuevas que aprendí fue crear virtual environments en Anaconda, el consumir documentación de Bibliotecas, el aprender a usar funciones lambda y apply en Pandas y, por supuesto, ggplot y Altair.
Hacer las gráficas “base” es muy sencillo una vez que se entiende la gramática de las gráficas. En estos ejemplos eso me llevo como 1/3 del tiempo total. El resto del tiempo se me fue en buscar los elementos exactos que tenía que modificar para obtener el resultado que quería.
Como se habrán dado cuenta, los códigos para hacer los dataframe es muy similar en R y en Python. Cosa muy diferente en las gráficas. Ahí los códigos de Altair fueron siempre más grandes. Esto no quiere decir que sea peor o algo por el estilo. En honor a la verdad Altair siempre estuvo en desventaja porque la primera gráfica siempre la hice en ggplot y dejé que muchas cosas salieran con sus defaults que no son los mismos que en Altair. Eso significó que investigara mucho en éste para poder hacer la gráfica lo más similar a ggplot. Si lo hubiera hecho al revés, seguramente hubiera usado más líneas en ggplot. Lo que quiero decir es que no le hagan el feo a Altair. Es muy útil sobre todo si quieren moverse después a hacer gráficas con D3 y JavaScript. Hay elementos que vienen de ahí así que ya tendrían mucho contexto.
Otra recomendación es que le inviertan algunas horas a ver los ejemplos que hay en la documentación de ambas bibliotecas o a ver videos. Hay muchos tutoriales en internet, que me salté por desesperado, que pueden hacer muy rápido para no desgastarse tanto. Es difícil seguir adelante cuando las horas se van acumulando y el proyecto no termina. A veces esto parece carrera de resistencia.
Por último: diviértanse. Esto del dataviz es una chulada. Agarren un tema que les apasione, jueguen con él y compartanlo con la comunidad
Recursos
Sin la ayuda del amigo @tacosdedatos, de Simplificando Datos y de la Data Visualization Society no habría terminado todo este proyecto. Dense una vuelta por sus perfiles y aprendan de todo lo que comparten.
El repo con las gráficas y todos los códigos están en https://github.com/nerudista/DataViz/tree/master/Pats. Siéntanse libre de jugar con él. ***
¿Qué te pareció la nota? Mandanos un tuit a @tacosdedatos o a @nerudista o envianos un correo a ✉️ sugerencias@tacosdedatos.com. Y recuerda que puedes subscribirte a nuestro boletín semanal aquí debajo.
Subscríbete a 🌮 tacos de datos | Aprende visualización de datos en español.
Recibe las mejores publicaciones directamente a tu caja de entrada